
一、chat 聊天框
chat聊天框内置了 Ask、Manual、Agent 三种固定模式和自定义模式
- Ask 直译过来就是问的意思
- Manual 就是手动的意思
- Agent 则是代理的意思,也可以理解为全自动模式
- 自定义模式:即 Add custom mode 选项,如果下方没有这个按钮,你可以点击 Cursor 右上角设置按钮,然后点击 Chat,找到 Custom mode 选项,开启这个,chat聊天框就会出现 Add custom mode 选项
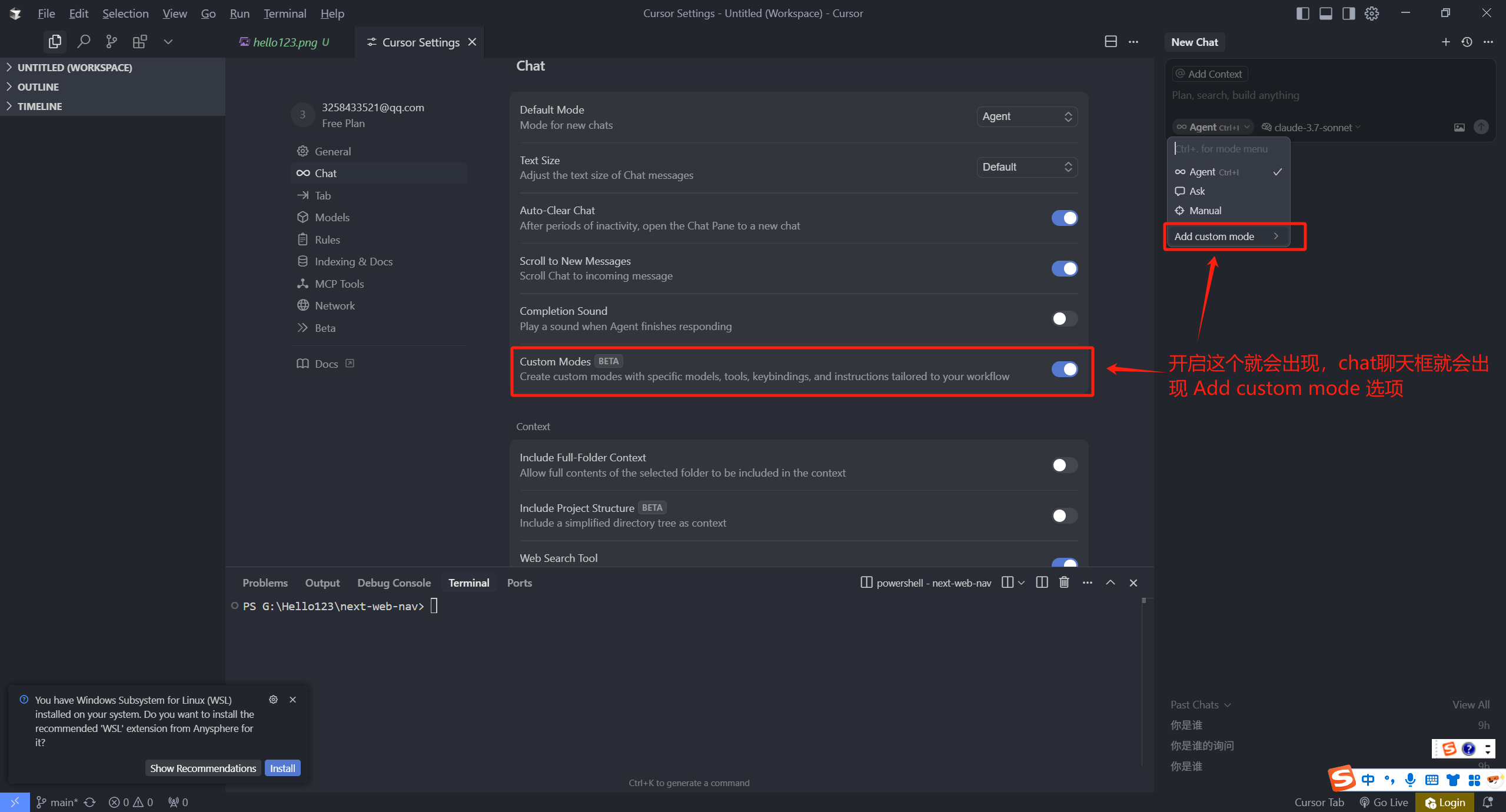
1.1 Add custom mode
我们来看一看这个自定义选项,点击 Add custom mode,我们可以设置自定义模式的名字、默认模型、快捷键
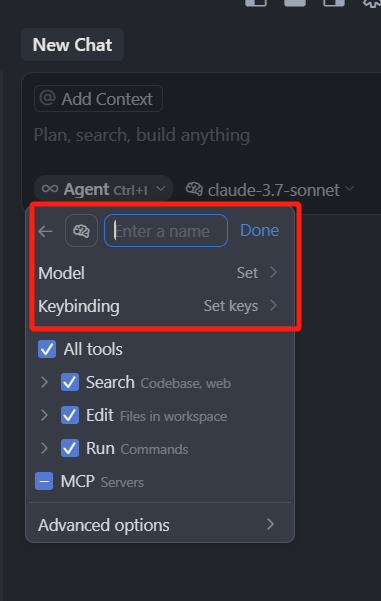
最重要的是,这个自定义模式,可以自己选择调用的工具有哪些,默认所有的工具都是选中的
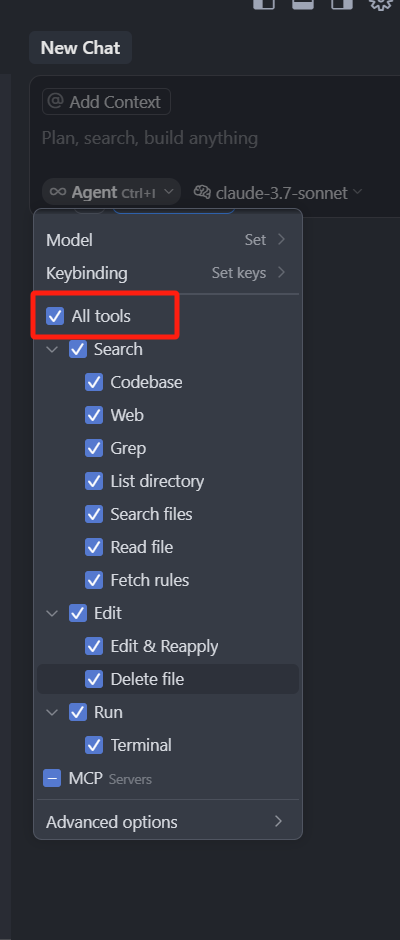
我们把所有的工具都取消掉, 然后一个一个来看,首先是 Search
1.1.1 Search 模块
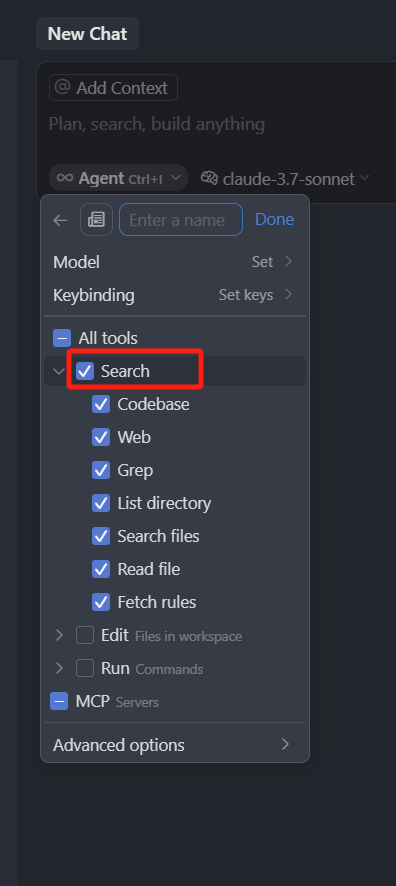
Search 就是搜索的工具,Cursor 里的搜索模块细分出了很多小工具,我们一个一个来介绍,首先是 Codebase
可以叫它语义搜索,其实,在我们打开一个文件夹作为项目时,Cursor 会有一个 Codebase indexing 的操作,它会自动采集项目文件夹下的代码,将这些代码,分割成一小块一小块的数据,把每个小块依次发送到,Cursor 的服务器上,Cursor 接收到数据之后,会使用 Embedding API 进行嵌入,把这些文件的相对路径,也一块存到远程的矢量数据库中,这样就可以利用索引,来提高答复的质量。
如果我们发送了一个问题,需要使用 Codebase 功能时,Cursor 会根据我们的指令,按照语义,对之前采集到的整个项目的文件,进行索引、排序、推理,最后给出一个匹配度由高到低的相关文件列表,这其实是一个在整个项目中,搜索与我们的问题描述最匹配的文件的过程。
在之前的 0.44 版本中,我们需要在问题中携带 @Codebase 指令来让 Cursor 知道,让cursor根据我的问题描述,先去匹配相关文件再回答。
在新版本中已经移除了这个指令,它变成了一个自主搜索工具(cursor自己判断是否需要使用这个工具)。新版本中使用 Ask 和 Agent 两种模式时,Cursor 会自主选择是否调用这个工具(会自己判断是否调用,调用与否我们无法掌握);而 Manual 模式则不支持自主调用这个工具,那由于新版本中去掉了 @Codebase 的指令,也就是说,Manual 模式不管是自动还是手动,都不再支持 Codebase 的功能。
再来看 Web,在输入框中,可以通过 @Web 指令来让 Cursor 知道要先去网络上检索一下我问的内容
这其实也是一个联网搜索功能,不同的是,它可以根据问题的描述,先去搜索网络上的内容,返回搜索结果。所以这里的 Web 也被作为了一个自主的搜索工具,那同样在 Ask、Agent 模式时,Cursor 会自主选择是否调用这个网络搜索工具。而在 Manual 模式则不能自主调用这个网络搜索工具,那如果我们要在 Manual 模式中,使用这个网络搜索工具,需要手动在输入框中,输入 @Web 指令,来告诉 Cursor,你需要先去网络上检索我的问题,结合检索到的结果再回答我。
再往下是 Grep,这是一个用来精准检索关键字,或者说字符串的搜索工具
比如你让检索项目文件中的某个函数,你可以直接在输入框中,发送一个函数名,Cursor 就会调用这个工具,来帮我们全局检索。同样在 Ask、Agent 模式中是自主调用的,而在 Manual 模式中不会主动调用这个工具。
再然后是 List directory,这个看名字就可以看出来,它是一个列表目录检索的工具,它可以读取我们的目录结构,这个工具的速度其实很快,因为它并不会直接读取文件的内容,而是只读取目录。同样在 Ask、Agent 模式中是自主调用的。而在 Manual 模式中,不会自主调用这个工具。
再接着是 Search files:
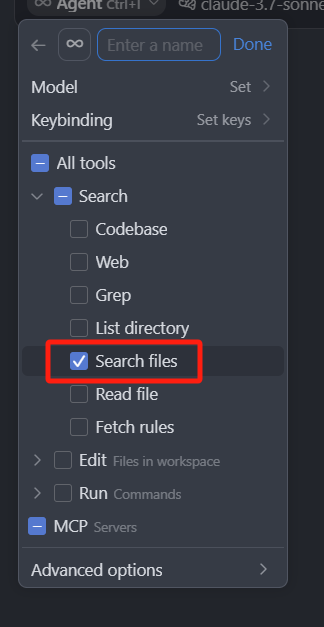
Search files 是一个使用模糊匹配,按照名称快速查找文件的一个搜索工具。同样在 Ask、Agent 模式中是自主调用的。在 Manual 模式中不会主动调用这个工具。
然后是 Read file,也好理解,读文件。
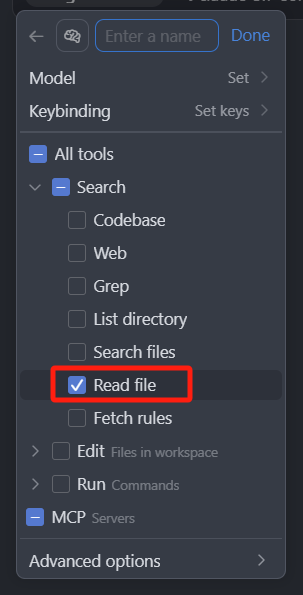
这个工具用来读取项目中文件的内容,一般来说的话,一次最多读取 250 行代码,如果我们开启 Max 模式,最多一次可以读750 行代码。
同样在 Ask、Agent 模式中是自主调用的,而在 Manual 模式中,不会自主调用这个工具。如果想在 Manual 模式中,读取某个文件,就要手动的使用该工具去选中某个文件,它才会调用这个读取文件的工具。
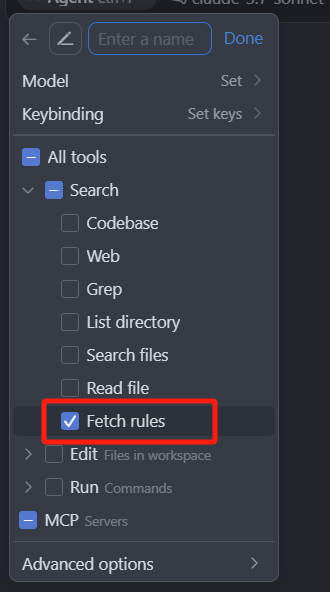
最后是 Fetch rules,这个和我们后面要讲的 Cursor rules 功能有关。它是一个根据规则类型和描述检索,获取特定规则内容的一个工具,这里我们简单了解就可以,因为后面还会重点讲 Cursor rules。同样在 Ask、Agent 模式中是自主调用的,而在 Manual 模式中,不会自主调用这个工具。如果想要在 Manual 模式中,使用某个规则,还是需要手动的去选中某个规则,它才可以使用这个规则。
Search 模块我们大概了解完之后,我们再来说 Edit 的模块。
1.1.2 Edit 模块
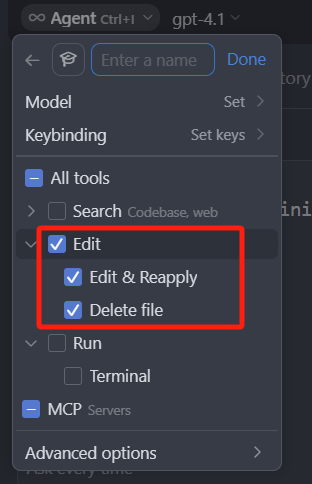
这个模块只有两个工具,看名字就很好理解,第一个是 Edit & Reapply 就是编辑文件,重新应用文件的一个工具;第二个是 Delete file ,是删除文件的一个工具。
整个 Edit 模块,在 Ask 模式中都是不可用的,在 Manual 模式中 Delete file 也是不可用的,Edit & Reapply 功能在 Manual 模式中是支持的,但是我们需要手动选中一个,或者是多个文件才行,因为这个模式下并不会自主调用工具而在 Agent 模式下,这些工具都是自主调用的,这里还要提一个点,如果你在 cursor 的设置中,勾选了禁止删除文件这个选项,那即使在 Agent 模式中,依然也是不能自主删除文件的,毕竟设置大于一切。
1.1.3 Run 模块
说完了 Edit 的模块,我们接着来说 Run 模块,这个模块下面的工具,只有一个 Terminal 终端,这个终端工具在 Ask、Manual 模式都不支持,只有在 Agent 模式中会自主调用。
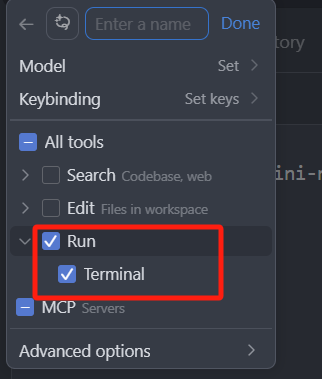
直接来给大家演示一下:
我们先选中 Ask 模式,输入一个需求(请你使用 pnpm 帮我初始化项目),回车,可以看到,Ask 模式的回复中,给了我们一些相关的命令,但是这个命令只是作为一个代码块,展示给我们,我们可以复制下来这个命令,粘贴到终端中,回车就可以运行这个命令。
当然也可以直接点击代码块右上角的 run,其实我们点击了 run 之后,cursor 就会帮我们复制下来,并且打开编辑器的终端,粘贴进去,然后自动回车运行。
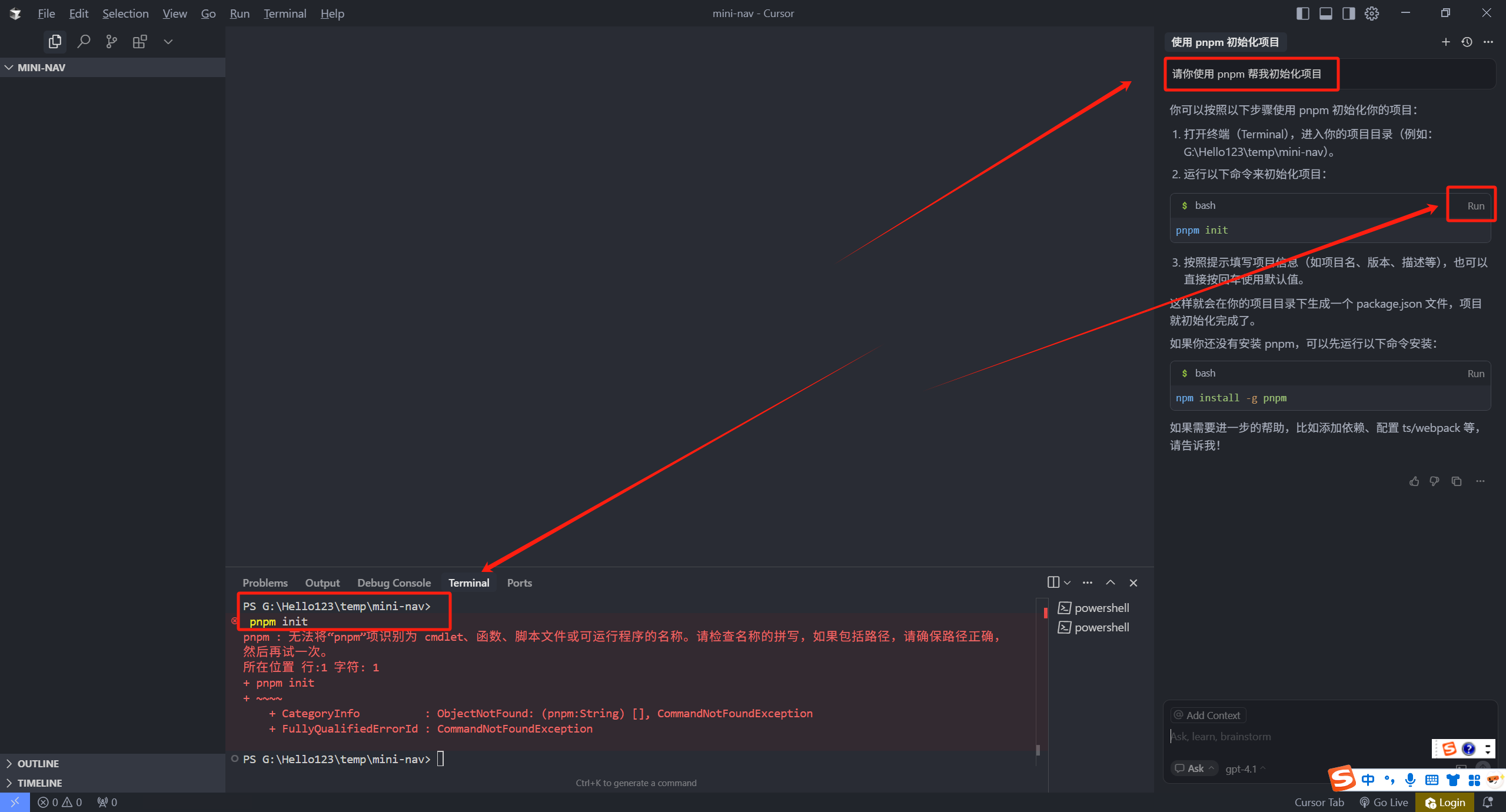
接着我们新开一个上下文,选中 Manual 模式,还是同样的问题,可以看到,他的回答其实和 Ask 是一样的,回复的都是代码块。
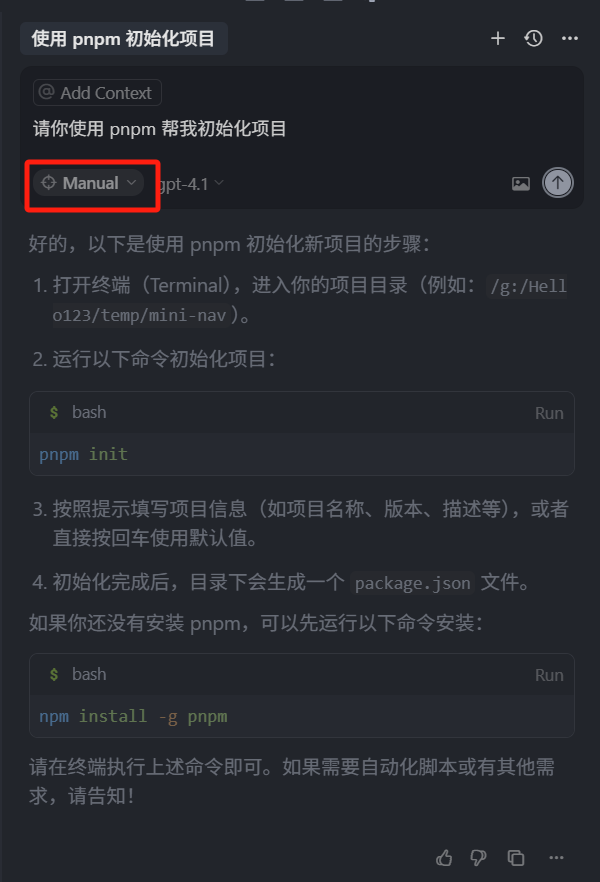
试想一下,这种方式不是很友好。因为即使我们手动点击代码块右上角的 run,自动帮我们粘贴到终端,并且运行这个命令,但是假如这个命令运行的时候有问题,模型是不知道的,我们还是需要去手动的复制终端的错误信息,粘贴到 chat 聊天框中。
我们再来打开一个新的上下文,选中 Agent 模式,还是同样的问题,回车。
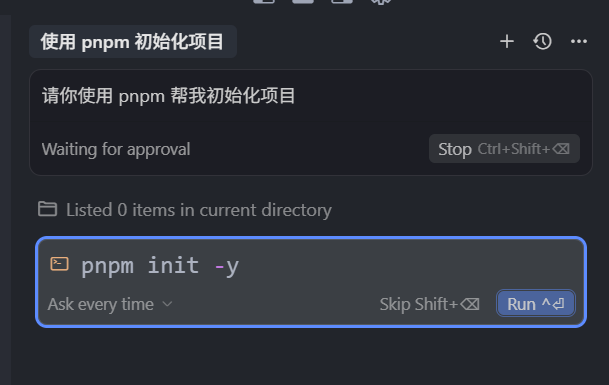
可以看到,Agent 模式下,回复的命令并不是一个单纯的代码块,而是一个可以直接运行命令的终端 UI 窗口,那在 0.49 版本后也上了一个新的功能,它允许我们去修改 Agent 的模式中,即将执行的命令。简单来说,就是如果模型给我们回复的命令,我们看着不太对,也可以去点击修改一下,然后再点击 run 去运行。
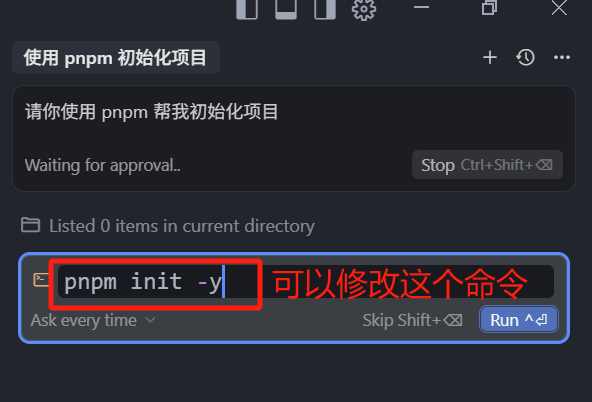
这里的 run,和之前的代码块中的 run 是不一样的,这里的 run 点击之后,它会在聊天框中直接拉起一个终端,帮我们执行这个命令。也就是说,执行之后,无论是成功还是失败,模型都会知道,并且给予我们答复。如果失败了,模型也会根据失败的信息,帮我们继续处理,而这个嵌入的终端,就是我们刚刚说的:Run 模块的 Terminal 工具。在默认的3种模式中,只有 Agent 模式可以自主调用 Terminal 工具。
可能有很多朋友会说,还是要我自己点一下 run,才能运行命令,这也不智能啊,针对这一点的话,如果你想让模型在 Agent 模式中,不询问就自动运行命令的话,也可以直接在设置中去设置,这个我虽然不是很建议,但是后面也会详细给大家介绍这块。
1.1.4 MCP 模块
我们接着回到自定义模式的配置选项,那 run 模块说完之后,我们接着来说 MCP。MCP 模块展开之后,就是我们自行添加的,所有的 MCP Server 的列表。
这个功能,我们后面会单独做一个章节介绍,现在就不细讲了,我们只需要知道,Agent 模式中是可以自主调用 MCP Server 的,而在 Ask、Manual 模式中无法调用 MCP Server。
1.2 Advanced options 高级选项
最后我们点击 Advanced options 高级选项,可以看到这里有三个选项,Auto-apply edits,Auto-run,Auto-fix errors。
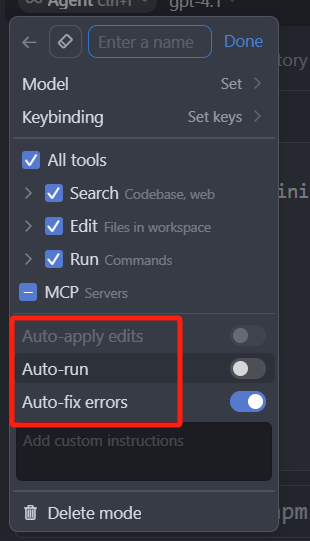
- Auto-apply edits 自动应用编辑;
- Auto-run 是自动执行终端命令,并且接受编辑;
- Auto-fix errors 自动解决引用错误和警告。
这三个都是 Agent 模式中支持的,可以自由配置的自动选项,所以我们要先明确的是,这几个选项和 Ask、Manual 模式无关,只在 agent 模式会被用到。
1.2.1 Auto-apply edits 自动应用编辑
先来说一下 Auto-apply edits 自动应用编辑,给大家演示一下就明白了,我们先开一个上下文,Agent 模式下输入一个任务,回车
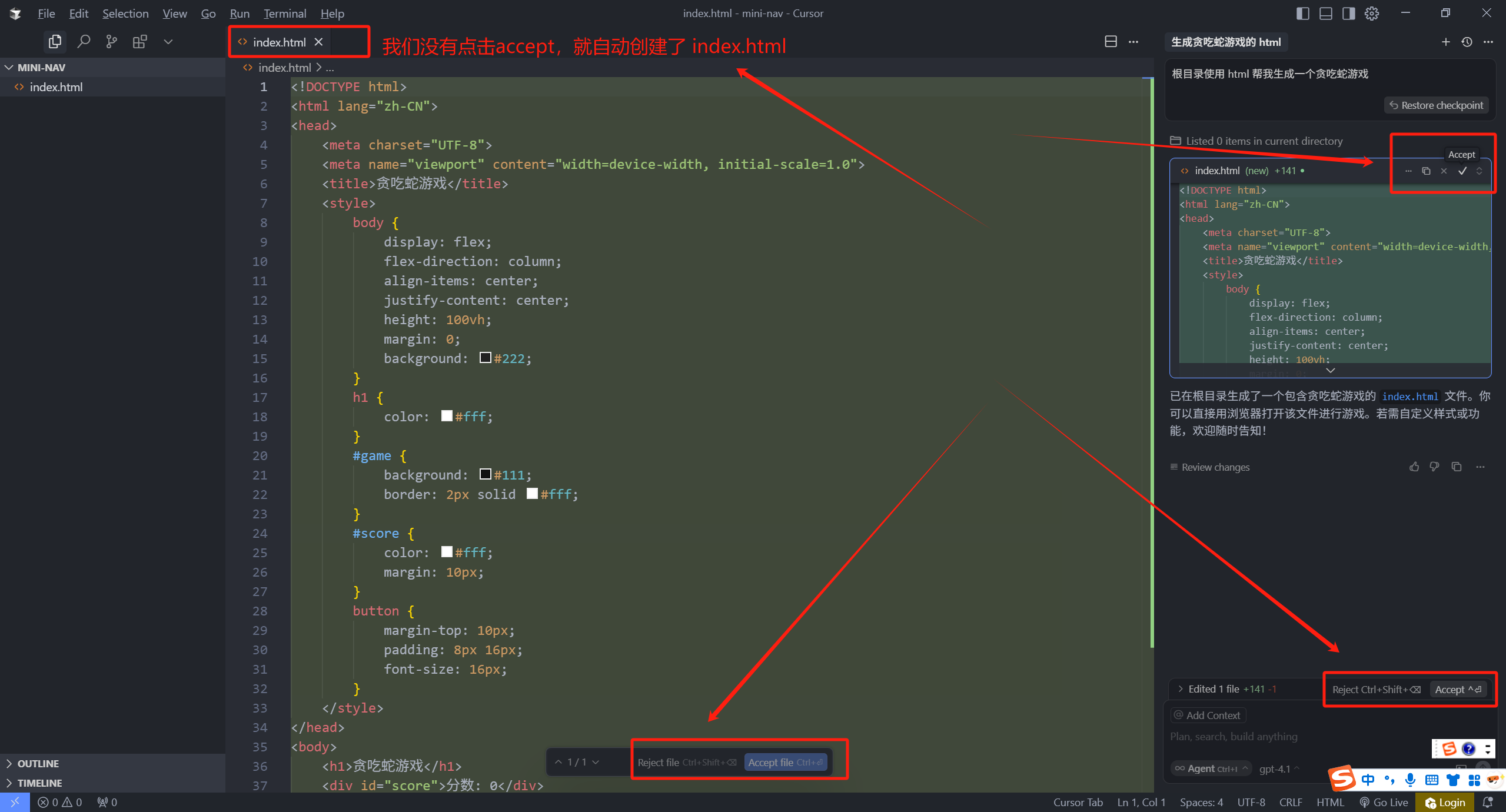
可以看到,它帮我们生成了一个,贪吃蛇的游戏代码。这个时候,其实 Cursor 已经帮我们自动应用了它生成的代码,我们可以点开看一下,它会有一个 Accept 接受 和 Reject 拒绝接受选项,让我们去选择,我们在左侧也可以直接点击 Accept all、Reject all 来全部接受或者是全部拒绝。
千万不要把应用 apply 和接受 accept 两个概念搞混,应用是 Apply ,可以理解为代码已经给你修改并且保存了,应用之后,你在其他编辑器中,打开目标修改的文件,其实就可以看到代码已经改变了,所以我们可以直接去查看效果,这个叫应用。所以我们这里说的是自动应用 apply,而不是自动接受 accept。接受与拒绝还需要我们自己去决定。
但是应用之后,Cursor 还会有一个保护措施(提供了 accept 和 reject 选项),在本地会缓存“修改记录”,可以点击接受 accept 来告诉 Cursor 你改的是对的我接受,或者点击拒绝接受,告诉 Cursor 你改的不对,我拒绝接受。点击拒绝之后,代码就又被恢复到了之前的样子,这是应用 apply 和接受 accept 两者的区别。
其实在早期的版本中,Cursor 生成代码之后,并不会自动应用 apply 代码,需要我们点击保存才可以应用,应用了之后,我们就可以去重新看一下代码,运行效果,来决定是否接受 accept 这个更改,但是我没有记错的话。在 0.46 版本之后,Cursor 修改代码之后就会自动应用了。
1.2.2 Auto-fix errors
然后接着讲下一个功能,我们先来说 Auto-fix errors,这个功能比较简单一点,我这里就不演示了,我们在让 Cursor 修改代码的时候,如果它修改后,代码有一些语法上的错误,或者是警告,如果你开了这个功能,这个时候 Cursor 会自动再帮你去处理,解决这个语法错误或者是潜在的问题警告。那如果你没有开这个功能,Cursor 按自己的心意修改完代码之后,就结束了,不会管你的语法错误或者是警告。
那这个功能在 Cursor Agent 模式中默认是开启的,如果你想关闭,可以点击右上角的设置点击 Chat 类目,往下滑找到这个,Auto-Fix Lints 选项,进行关闭和开启。我们在设置中,如果关闭了这个选项,除了 Agent 模式关闭了这个功能,还有就是,即使你在自定义模式中,开启了 Auto-fix errors,它也是不生效的,这也是我们上面说的 cursor 的全局设置大于一切。
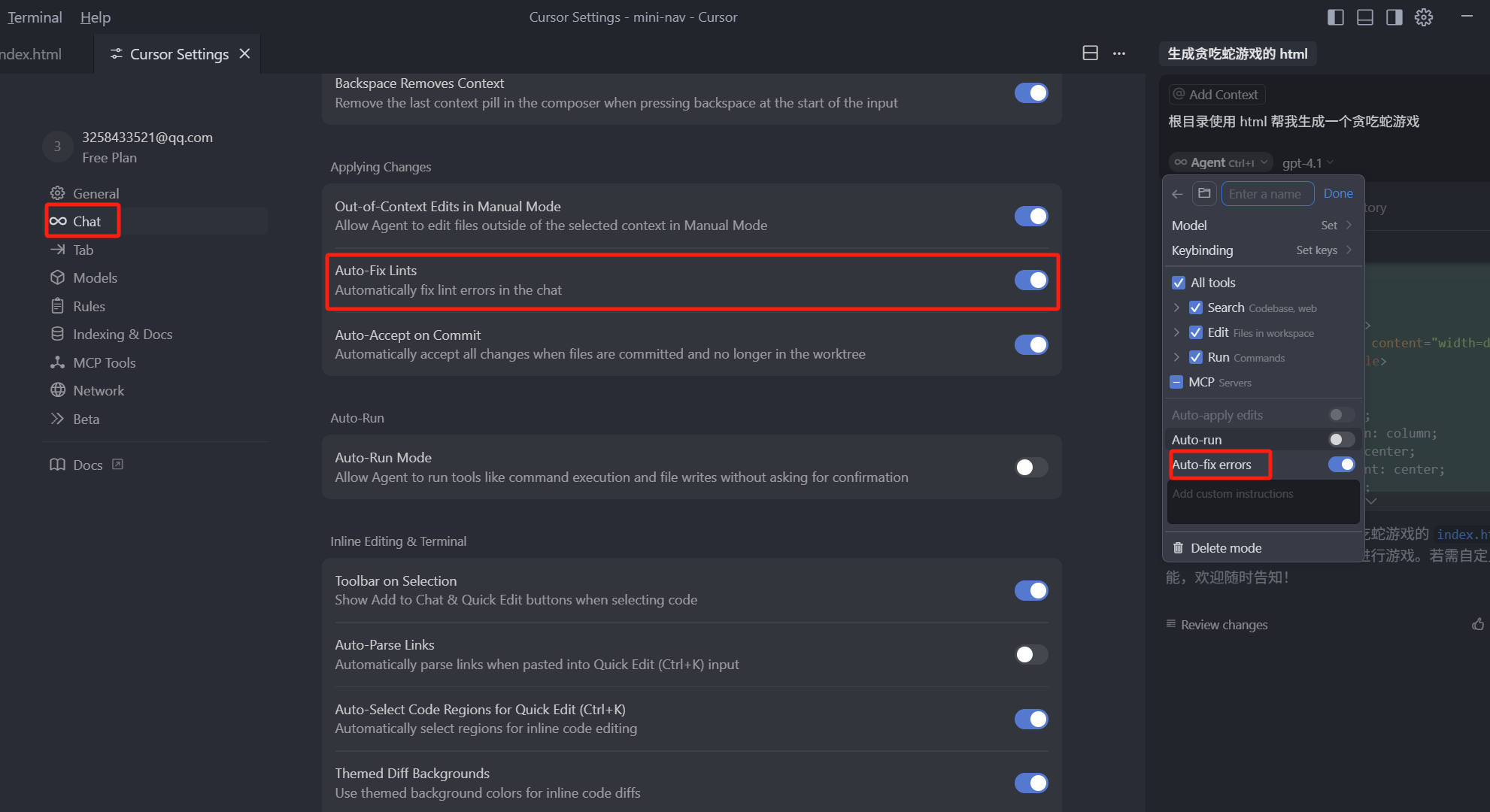
1.2.3 Auto-run mode
最后我们再来看 Auto-run,它是自动执行终端命令并且接受编辑,这就是我们之前讲终端工具时说的,如果你想在自定义模式中,让这个模式自动运行终端命令,并且自动接受编辑,就可以打开它,注意这里是自动接受编辑 Accept,而不是应用 Apply 。
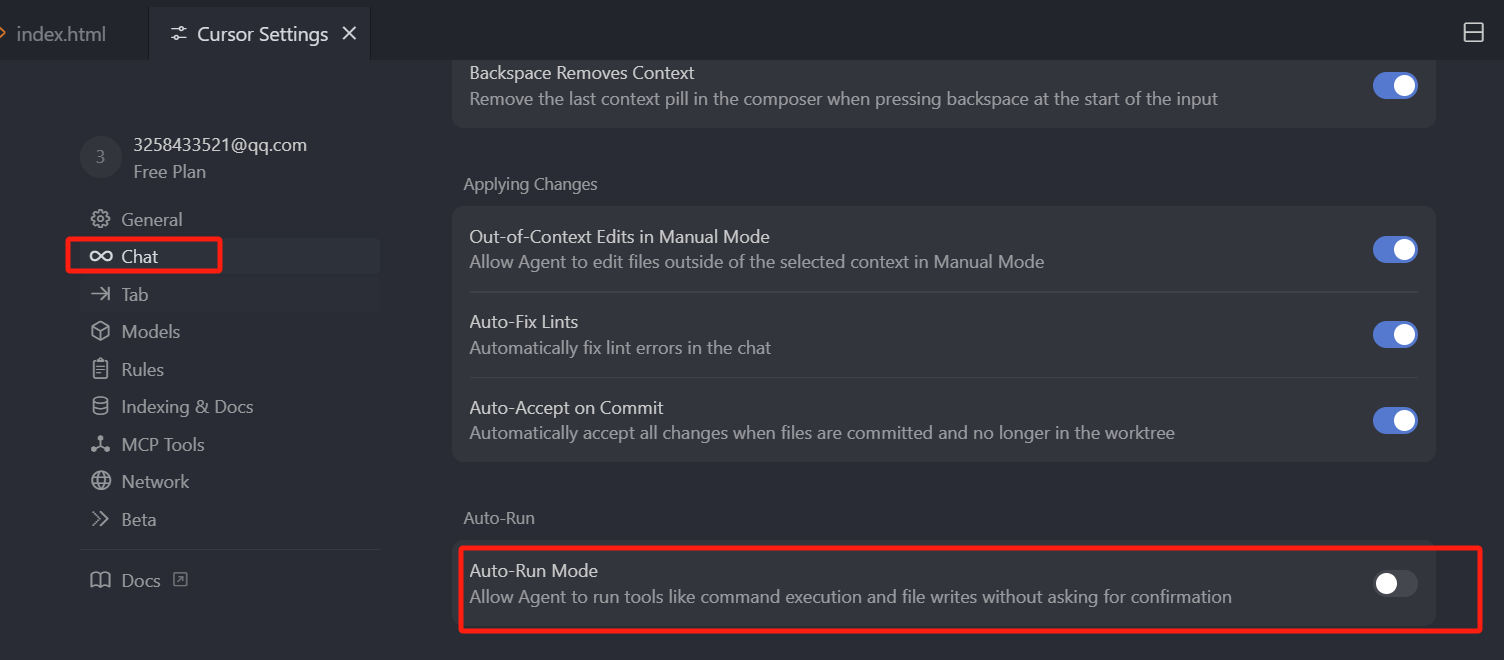
同样我们也可以在设置中,详细的配置 Auto run 的选项,还是在设置中 Chat 类目下找到 Auto run mode,这个其实早期版本叫 yolo 模式,应该是在 0.46 版本之后,改名成了 Auto run 模式,默认这个功能是关闭的,所以我们现在在 Agent 模式中,依然要手动点击执行终端命令,并且手动接受编辑。
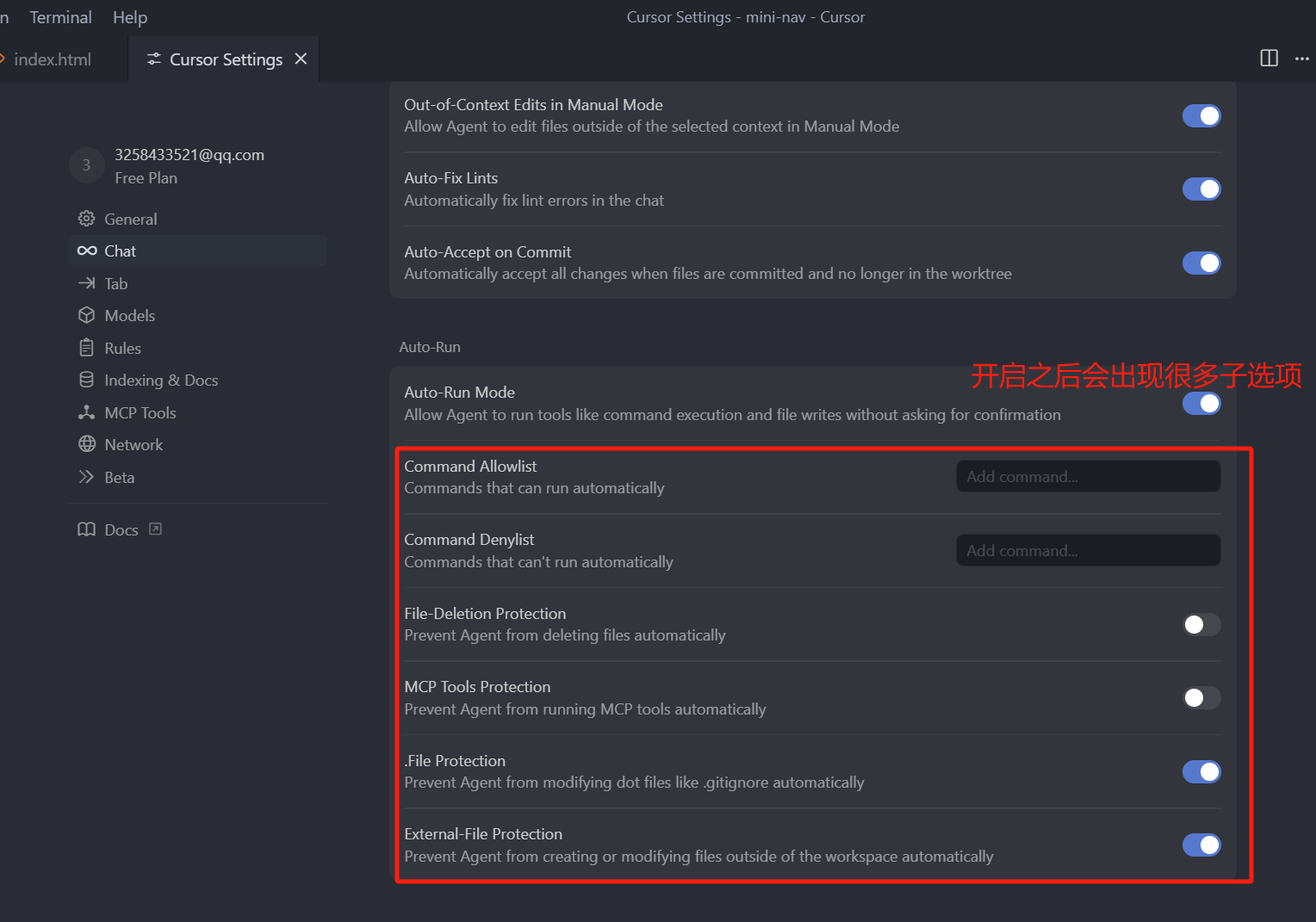
那我们开启了它之后,就可以打开自动运行模式,我们可以看到这个配置项中有很多子项,如果你打开 Auto run mode 这个选项的话,我们就需要了解一下这些子项,首先是 Command Allowlist 和 Command Denylist,这两个是对应的,如果你觉得自动让 Cursor 执行命令太不安全了,但是又想要这个便捷的功能,你可以在这里设置允许哪些命令自动执行,或者不允许哪些命令自动执行。
往下是 File-Deletion Protection,这个是删除文件保护,如果你开启了这个选项,那么 Agent 模式中就会禁止删除文件。
接着是 MCP Tools Protection,这个是 MCP工具保护,如果你开启了这个选项,那么 Agent 模式中就会禁止运行 MCP Server。
再往下是 .File Protection,这个是点(.)文件保护,默认它是打开的,因为基本上我们开发中,以点开头的文件(比如 .env 文件),要么是配置文件,要么是环境文件,这些文件都比较重要,所以禁止 Agent 模式自动去修改点开头的文件,还是很必要的。
再往下是 External-File Protection,这个是外部工作区保护,是否禁用 Agent 模式自动创建,或者是修改工作区之外的文件。这是什么意思呢,就是如果在 Cursor 中打开了一个文件夹,那这个文件夹就是我们的工作区。
其实早期版本的 Cursor 是只能修改工作区之内的文件,那随着后面的更新如果你指定让 Cursor,帮你修改一个工作区之外的文件,Cursor 也是可以修改的,但是这个操作是极其危险的,因为在 Agent 模式中一旦打开了自动运行选项,有可能你没有注意,它就改了一个外部文件,所以你在开启自动运行 Auto-run 选项时,这个外部工作区保护是自动开启的,这样它会更安全一些。
上面这些,就是我们在打开自动运行 Auto-run 模式时,可以手动控制的一些自动的颗粒度选项,它可以帮助我们更好更安全的使用 Auto-run mode 模式。
我建议代码能力稍弱,对 Cursor 理解不够深入的朋友们,尽量不要开启自动运行模式,因为如果你无法控制模型的输出粒度,而且对代码还不熟悉,开了之后乱改的风险就会很大,到这里我们就简单介绍完了自定义模式中可以配置的一些选项。
当然我们的目的不是为了让大家去自定义模式,而是为了帮助大家更好的理解默认的 3 种模式(agent、ask、manual)的区别,有关自定义模式的使用场景,我们在后面的使用技巧中会再提到。
我们可以通过自定义模式的功能,来总结一下 Ask、Manual、Agent 三种模式的区别:
- 其实 Agent 模式最简单,因为 Agent 模式就是包含了这些自定义选项中的所有工具的自主调用;
- Ask 模式包含了所有 Search 模块中工具的自主调用;
- Manual 模式则是没有自主调用,只能通过手动指令去触发某几个工具的调用。相比于老版本中的 Composer normal,新版本中的 Manual 模式做的非常简单。并且直接让这个模式只关注用户的指令去做事情,变成了一个纯手动的模式,完全受控于用户。 那现在你清晰了吗?
二 大模型
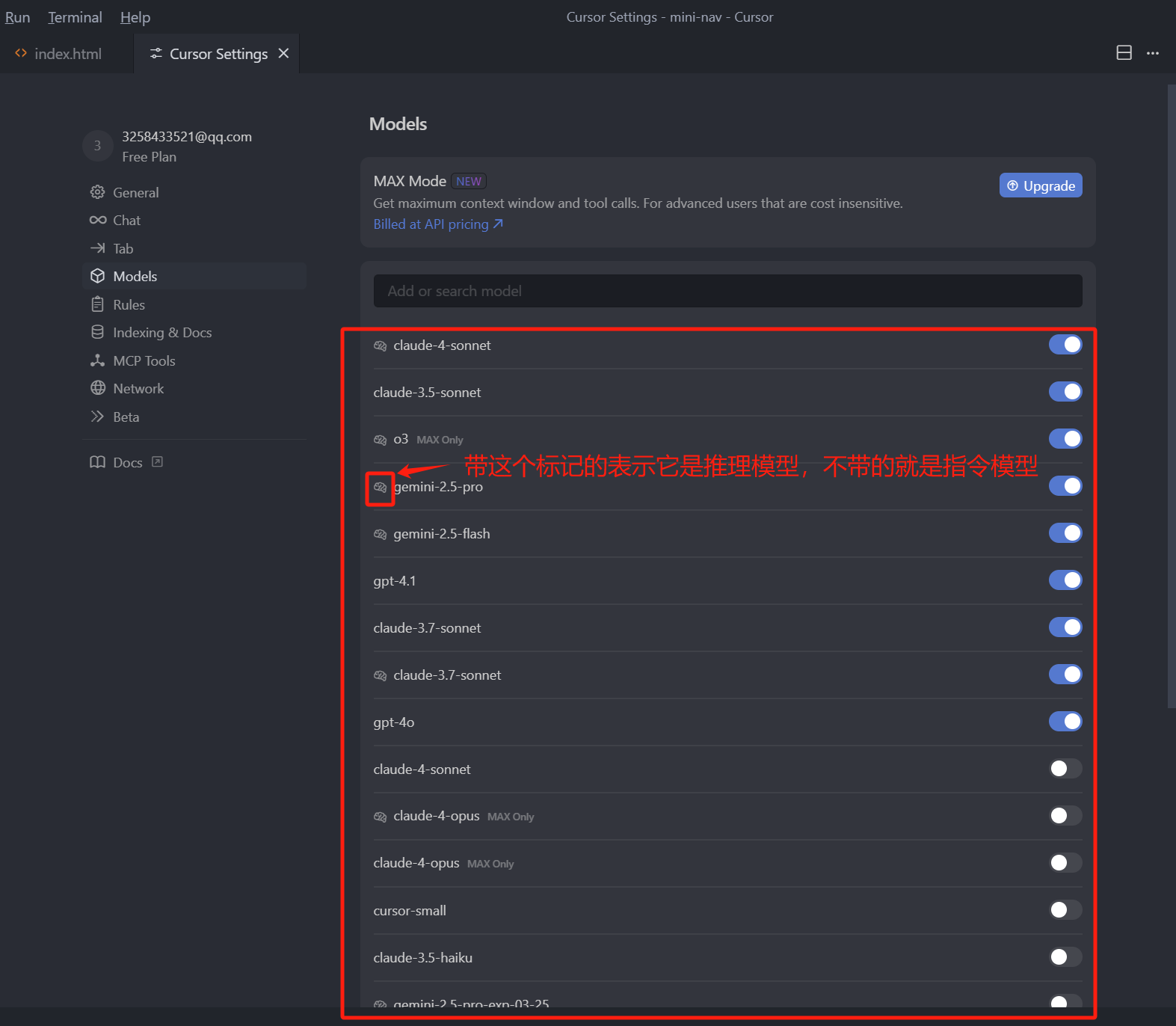
接着聊一聊 Cursor 中支持的这些大模型,同样还是点击 Cursor 编辑器右上角的设置按钮,然后点击 Models,右侧我们就可以看到,Cursor 支持的所有的大模型,基本上市面上比较优秀的模型都有。
除此之外,你也可以在下方选择填写模型提供商的账户密钥,这样就可以不使用 Cursor 内置的模型,但是我并不推荐大家这样做,因为虽然 Cursor 支持接入模型提供商密钥去使用,但是这种方式在 Cursor 中,会导致模型的很多功能是使用不了的,如果你就是想使用模型提供商密钥的话,我建议你直接去使用 Cline,或者是 Augment code,这两个都是以插件的形式集成在编辑器中的。
我们回到模型本身 ,Cursor 中内置的这些模型列表中,我们把想要使用的模型勾选上,这些模型就会出现在聊天框中的可选列表中,我们就可以在聊天框中点击选择模型去使用了。
其实在 0.50 版本之前,Cursor 的计费方式,以及模型都是比较混乱的,有免费的普通模型,有 Pro 会员可以用的高级模型,还有额外单独计费的几个模型,还有 Max 模式下单独计费的模型。终于在社区的激烈讨论中 0.50 版本做了更改,现在我们可以把 Cursor 中所有的模型分为三类:
- 第一类,免费的普通模型,比如 Cursor small、Deepseek V3、GPT-4o mini,这些模型的调用都是免费的,无论你付费不付费都可以使用,并不会限制我们的次数。
- 第二类是付费的 Pro 会员,可以使用的高级模型,比如 Claude-4-sonnet、Gemini-2.5-Pro 等等,这类模型是按次数计费,Pro 会员一个月是 500 次的快速高级请求,超出之后也可以用,只不过变为了慢速高级请求,慢速高级请求是可以无限制使用的,请求的优先级比较低,因此速度会比较慢,与快速高级请求相比会有些延迟,慢速请求其实还好吧,除非一些极特殊的情况会比较慢,大部分情况下都是可以接受的,所以大家也不要有额度焦虑。
- 第三类是开启了 Max 模式的高级模型,在最新的 0.50 版本中,几乎所有的高级模型,都可以开启 Max 模式,开启了之后,计费方式就变成了按照 Token 计费,这种模式下的模型,相当于是一个增强版。在聊天框中点击模型,模型的下拉中,我们就可以看到 Max Mode,另外这里展示了我们在设置列表中选中的所有模型,在模型名字前面,带有大脑图标的就是推理模型,而不带图标的就是指令模型。
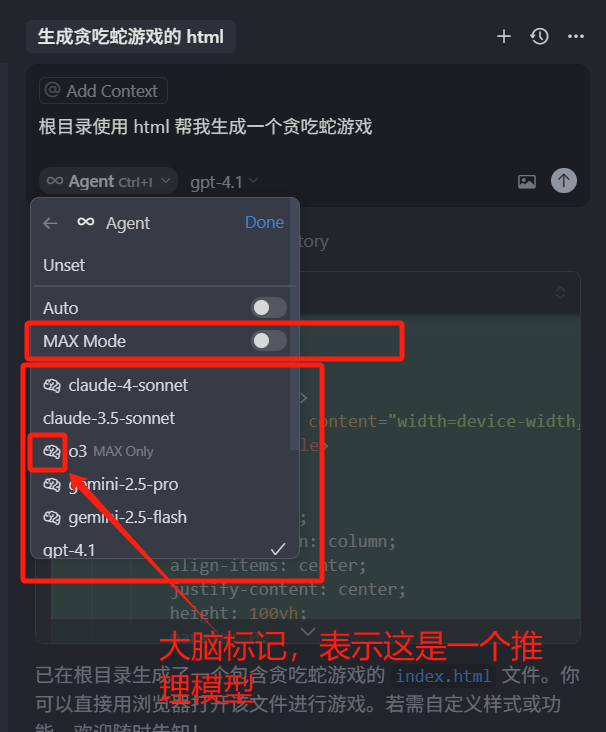
如果我们开启了上方的 Max mode 模式,就开启了 Max 模式计费,这个时候再选中模型,就会变为按 Token 计费,当然这样的话,也可以享受到,Max 模式最大限度的功能体验(这就是另外的价钱了)。
下图中有一个 Auto 选项,一旦开启,Cursor 会根据性能和速度,自动选择最佳的模型去使用,打开这个选项之后,无需我们自行选择模型。
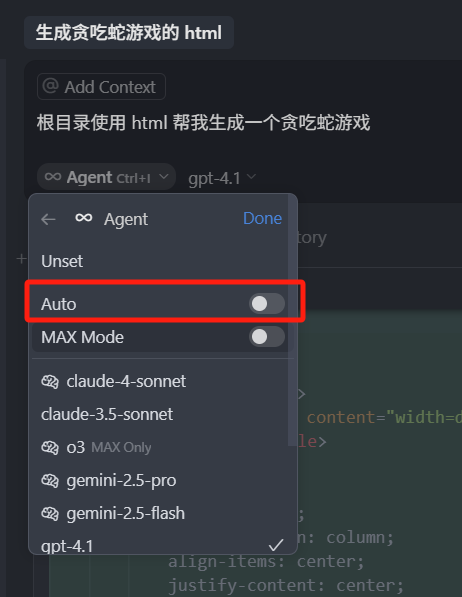
另外需要注意的一点是,如果我们使用,前面带有大脑图标的 Claude-3.7-sonnet 模型,一次会耗费两个次数,可以看到悬浮框中也有标识(我现在的 1.0 版本中没有这个标识了)。
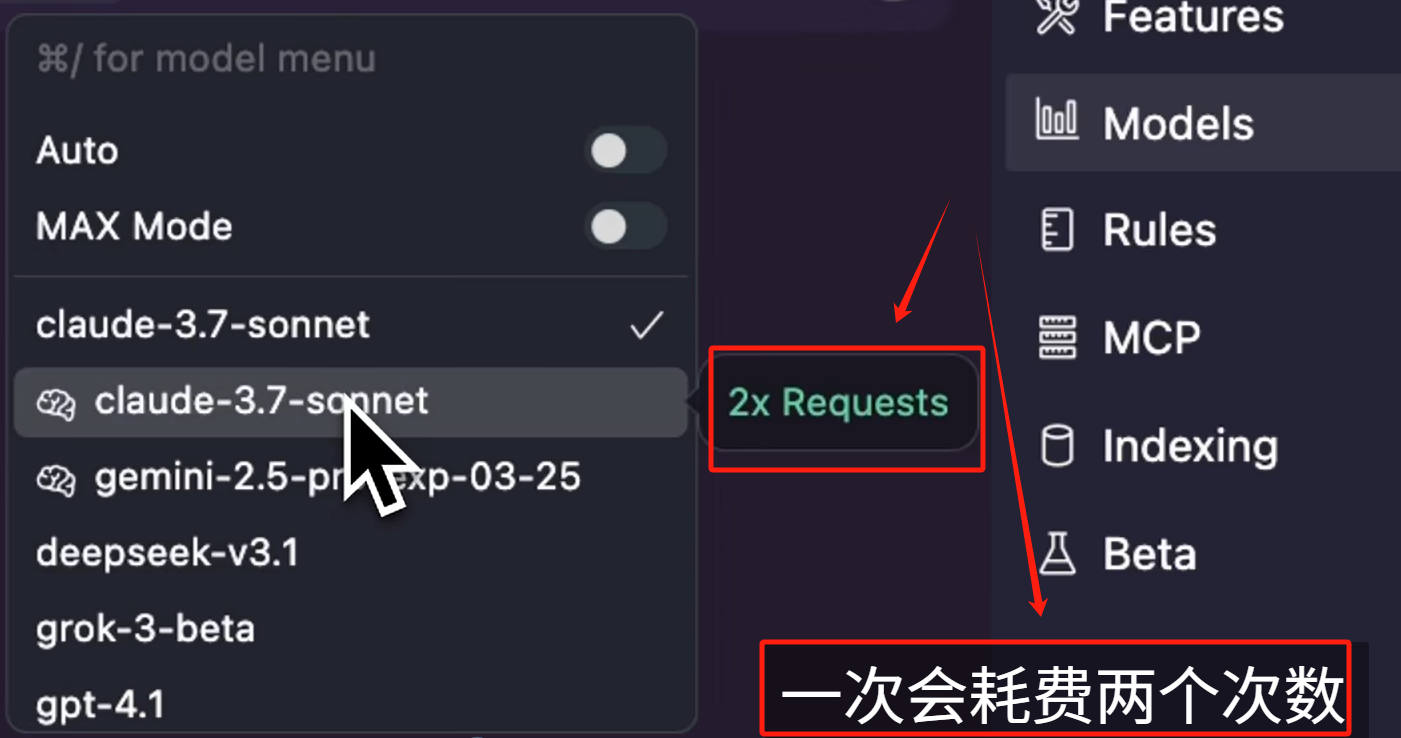
这是因为 Claude-3.7-sonnet 本身并不是一个推理模型,Cursor 给它加了一个推理的步骤,所以这一步推理需要额外记一次次数,当然其他模型本身就是推理模型的,比如 Gemini-2.5-Pro,还有 Deepseek R1 这种,一次请求还是只耗费一个次数。
我们再来说一下这个 Max mode 模式,也就是火力全开模式,在使用 Max 模式下的模型时,它会提供更大的上下文窗口和扩展的推理能力。并且使用 Agent 模式时,一次可以调用 200 个工具文件读取操作(正常只可以调用25个工具),一次最多可以处理 750 行代码(正常是可以处理250行),相当于是一个加大功率的增强版。
可能有朋友不理解,这个 Agent 模式下,一次调用 200 个工具是什么意思,这里可以额外补充一下:我们在使用 Agent 模式时,其实 Cursor 会让模型帮我们去规划任务,然后再执行任务,执行任务的过程中,模型会根据自身情况,自主调用我们前面讲过的那些@Codebase @Web 工具,默认情况下,一轮对话,自动调用工具的次数最多是 25 次,超过 25 次,Cursor 就会自动停止一下,当然这个时候你也可以手动点击,让它继续,但是只要超过 25 次,就会停顿一下。而 Max 模式把这个限制增加到了 200 次,这样说大家可能就明白了。
我们可以看一下示例:
可以看到,当我们发起一个问题时,Cursor 先调了一个工具,这个工具就是我们之前讲过的 List directory 的工具,这是一次工具调用,然后它后面又调用了两次 List directory 的工具,接着第四次工具调用是帮我们创建了一个文件,第五次调用是帮我们修改文件,就像这样,自动执行时,超过 25 次就会停止询问一下。
另外 Max 模式下文件读取,一次最多可以处理 750 行,这个大家可能没啥概念,但是我们只要知道,默认情况下,Cursor 的读取文件工具,一次最多可以读取 250 行,这样其实就有了一个对比的概念。
综上所述,Max 模式比较适合一些复杂的任务、或者是问题,它适用于一些大型上下文密集型操作,对于绝大多数任务来讲,其实普通的模式就可以了,当你的上下文不超过 10 万个 Token 时,使用 Max 模式的收益会小很多,当然壕哥请随意!
可能还有的朋友会问,这玩意好复杂,我有选择恐惧症,不知道怎么选,该怎么办,其实我们只需要记住两个点就好了。
第一,一般情况下不要使用推理模型,其实就效果而言,推理模型肯定是要比指令模型要好的,如果大家不知道什么是推理模型,什么是指令模型,你看一下我前面总结的《一文搞懂Deepseek》,也是看 up 主“不正经的前端啊”的视频教程总结的。
可能你还会问,既然推理模型效果好,为什么不用,其实原因很简单,推理模型太慢了,推理模型回答时,会先做推理,输出推理的回答,然后再根据推理的内容,去回答我们的问题,这个过程很漫长,并不是很适合在编程环境中使用,还有很重要的一点是,Cursor 中我们生成代码时,最常使用的是 Claude-3.7-sonnet 模型,这个模型使用推理时,推理和最终回答是两次,输出要耗费两个请求次数,当然,如果时间和次数对你来说都不是问题,推理模式肯定是最好的。
第二,在 AI 编程领域,Claude 模型是当之无愧的第一,所以没有什么可选的,能用 Claude 就用 Claude,而 Claude-4-sonnet,是目前最好的代码生成模型,没有之一,至少目前是这样,而且 Cursor 的很多新功能,首先适配的就是 Claude 模型。
另外,如果你只是单纯的向 AI 问问题,比如与 AI 交流梳理流程或者是需求,可以使用 Gemini-2.5-Pro 这个模型,在泛类的知识问答、需求梳理以及任务规划上,Gemini-2.5-Pro 的表现也相当优秀,但是由于它是一个推理模型,所以相对会慢一些,
总结一下,在 Manual、Agent 模式下,涉及代码生成,我们要首选 Claude -4-sonnet,次选 Gemini-2.5-Pro;在 Ask 模式下,单纯的问答,首选 Gemini-2.5-Pro 或者 Claude -4-sonnet,尽量不要勾选 Auto 模式,因为一旦选了 Auto 模式,它用什么模型我们是不知道的,这样的话会有很多不可控因素。
还有就是,我们上面说的这些模型的选择,前提是你在编程领域。如果你在 Cursor 中,做一些花里胡哨的事情,比如写写小说、写写文案什么的,那其他的模型也是可以选择的,但是在编程领域,无需多言 Claude。
三 Chat
在介绍完了 3 种内置模式、自定义模式以及模型之后,我们终于可以好好聊一聊 Chat,以及新版本的 Chat 面板了,其实我们会发现,现在的 Ask、Manual、Agent 模式,区分会更明确一些,而在新版本中,基于这 3 种内置模式的一个完整的聊天上下文,被称为一个 Chat。
在早期 0.44 版本中,一个聊天上下文只能使用一种模式,切换模式的话就要新开一个上下文,而新版本中,你可以在聊天上下文中任意切换模式,我们可以选中 Ask 模式,然后选中 Gemini 模型,输入你是谁,回车。
得到了答案之后,我们再切换为 Agent 模式 Claude 模型,输入你是谁,回车。

我们还可以持续性的问问题,问的过程中可以切换模式,也可以切换模型,那从第一个问题到最后一个问题,这是一个上下文,我们称为一个 Chat。
在早期的 0.44 版本时,这块儿一直是被人诟病的点,因为同一个上下文中,我们可能会问很多问题,但是这些问题在同一个上下文中,不能切换模式,也就造成了,不同模式之间的问答信息不能共享的问题,这块儿在新版本中也不再是问题,如果我们要新开一个 Chat,可以点击右上角的加号,或者快捷键 CMD+N(Win:Ctrl+N),就可以新开一个上下文,如果我们要查看之前的上下文,可以点击右上角的时间小图标,选中一个历史 Chat 即可。

我们新开一个上下文,然后输入一个问题,回车。等它开始回答了,我们再点击加号,新开一个 Chat,这个时候我们需要注意的是,如果 Cursor 正在回答我们的问题时,我们就新开了一个 chat,会弹出一个弹窗,让我们选择是新开还是取代原来的chat。
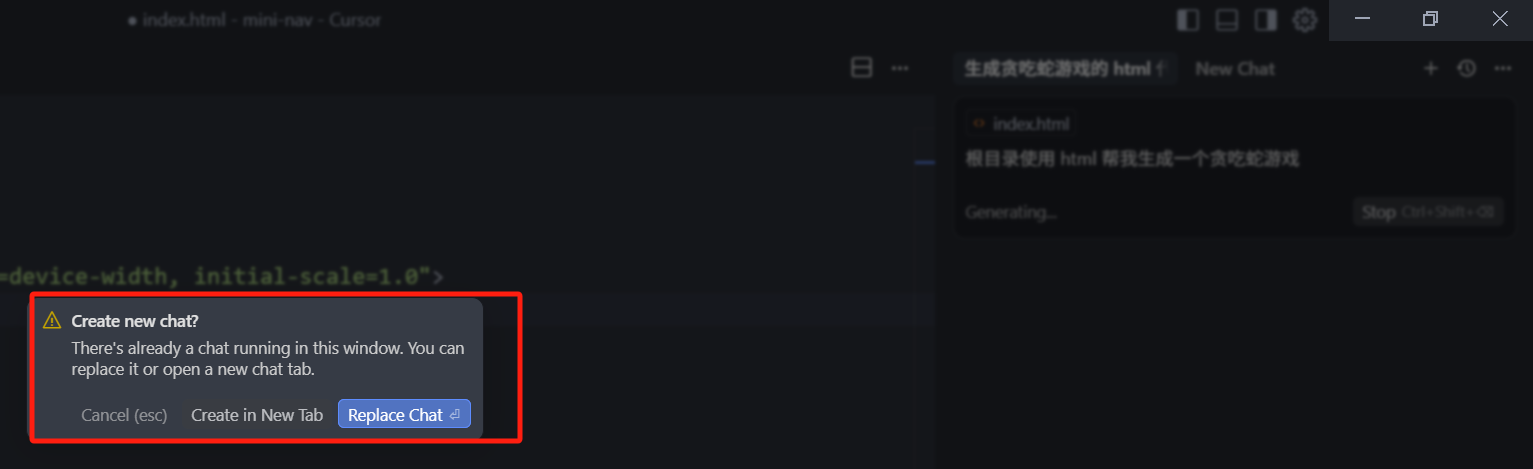
选择 create in new tab 就可以多开一个 tab ,就能实现并发地执行多个 Chat 。
大家可以把 Chat Tab,理解为浏览器的选项卡,区别是,浏览器中可以开无限个选项卡窗口,而 Cursor 中最多只能开 3 个 Chat Tab,也就是最高只支持 3 个并发的 Chat 任务,超出的话,第一个就会阻断执行,并且成为历史的 Chat,
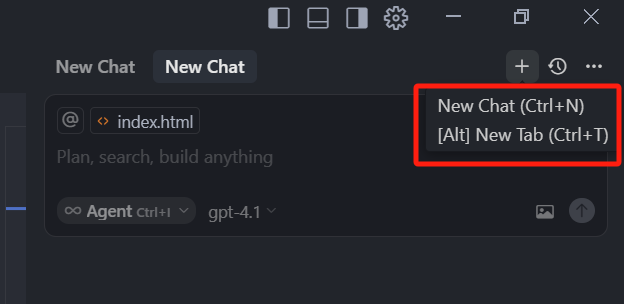
- Ctrl + N 是新开一个chat,如果之前的chat不是正在执行中,就会取代之前的chat,如果是正在执行的话,那就会新开一个 chat tab;
- Ctrl + T 新增一个 chat tab,也就是新增一个并行执行的聊天框。
任务完成的提示音效默认是关闭的,我们需要点击 Cursor 右上角的设置,然后点击 Chat 类目,找到这个 Completion Sound 选项,开启之后,就可以得到,一个任务完成时的提示音效。
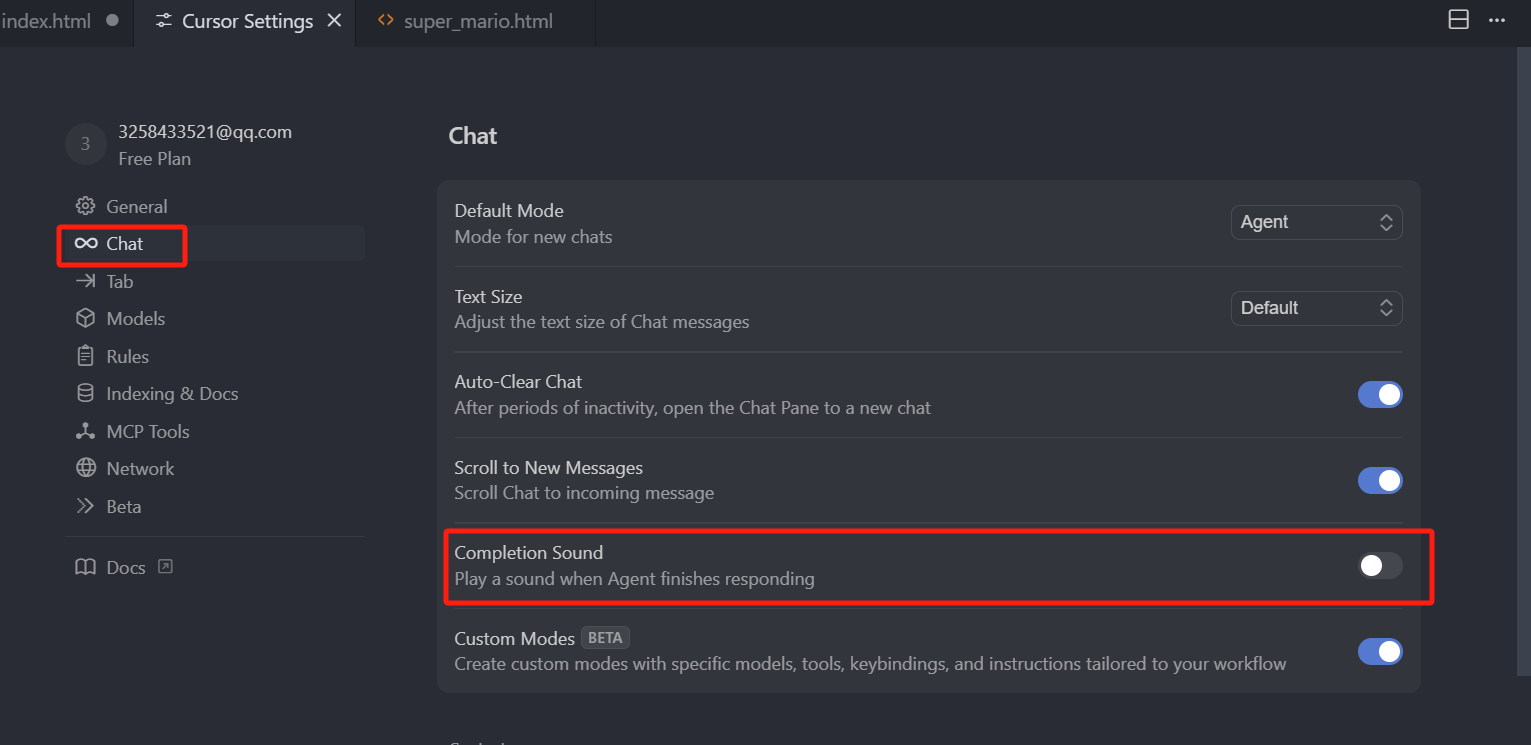
其实在之前没有上 Chat Tab 并发窗口时,大部分人的状态就是,一顿打字输入一个任务,然后静等 Cursor 完成任务,这中间甚至可以摸鱼水水群、喝杯咖啡,看个新闻什么的,总之一个大的任务输入进去,是需要一段时间去完成的,那现在有了这个功能之后,就可以并发的执行 3 个任务,效率会提升很多,那由于 Cursor 没有给这个功能开放一个可视化的点击入口,只能通过快捷键 CMD+T(Windows系统:Ctrl+T)新建一个 Tab,所以其实很多人不知道,但是这又是一个非常重要的功能,所以大家一定要知道并且用起来,它可以让我们的效率 * 3。
我其实建议你在打开 Cursor 时,就直接点击 Chat 输入框,然后 CMD+T(Win:Ctrl+T)、CMD+T(Win:Ctrl+T),把这 3 个 Chat Tab 建好再说,免得我们忘了这玩意儿还能并行。
那其实在 0.50 版本也上了一个功能,它叫做 Background Agent,是一个可以后台运行的一个 Agent 模式,也就是说,我们可以在后台,或者是远程运行一个任务,这个我们后面还会提到。
3.1 Symbol 模块
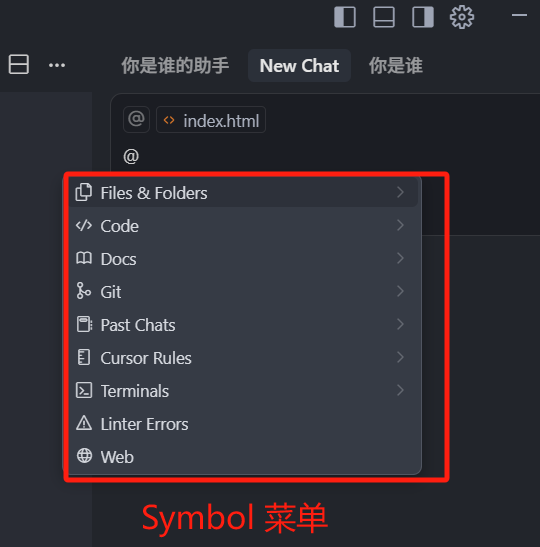
我们先开一个 Chat 上下文,然后进入到 Symbol 模块的学习,Symbol 就是符号的意思,我们要介绍的就是符号指令。
这里,我们会着重介绍一些相对于 0.44 以及之前版本 新增的 Symbol 指令,也会提一下删除掉的 Symbol 指令,
至于旧的依然还存在的指令,因为 up 主的上期视频详细讲过,这里会快速的介绍一下,这样不浪费大家的时间,
3.1.1 @Files & Folders
我们可以在 AI 聊天框中输入 @ 符号,唤醒 Symbol 菜单,首先是 @Files & Folders,它可以选中工作区的文件或者是文件夹,给到大模型,这样大模型就知道你的问题,跟这些文件或者是文件夹有关,除了输入 @ 符号选中文件或者是文件夹之外,我们也可以直接拖拽,工作区中的文件,或者是文件夹到输入框中,其实在早期版本中的 @Files、@Folders,是两个单独的指令,那新版本中将它们合并到了一起。
另外在 0.50 版本之前,我们只能选中项目下的文件夹,那在最新的 0.50 版本中,选中文件夹时,我们可以直接选中项目作为文件夹,也就是直接选中这个项目根目录。
那同时 Cursor 也上了一个新的功能,我们打开右上角的设置之后,点击 Chat 类目,找到一个叫 Include Full-Folder Context 选项。
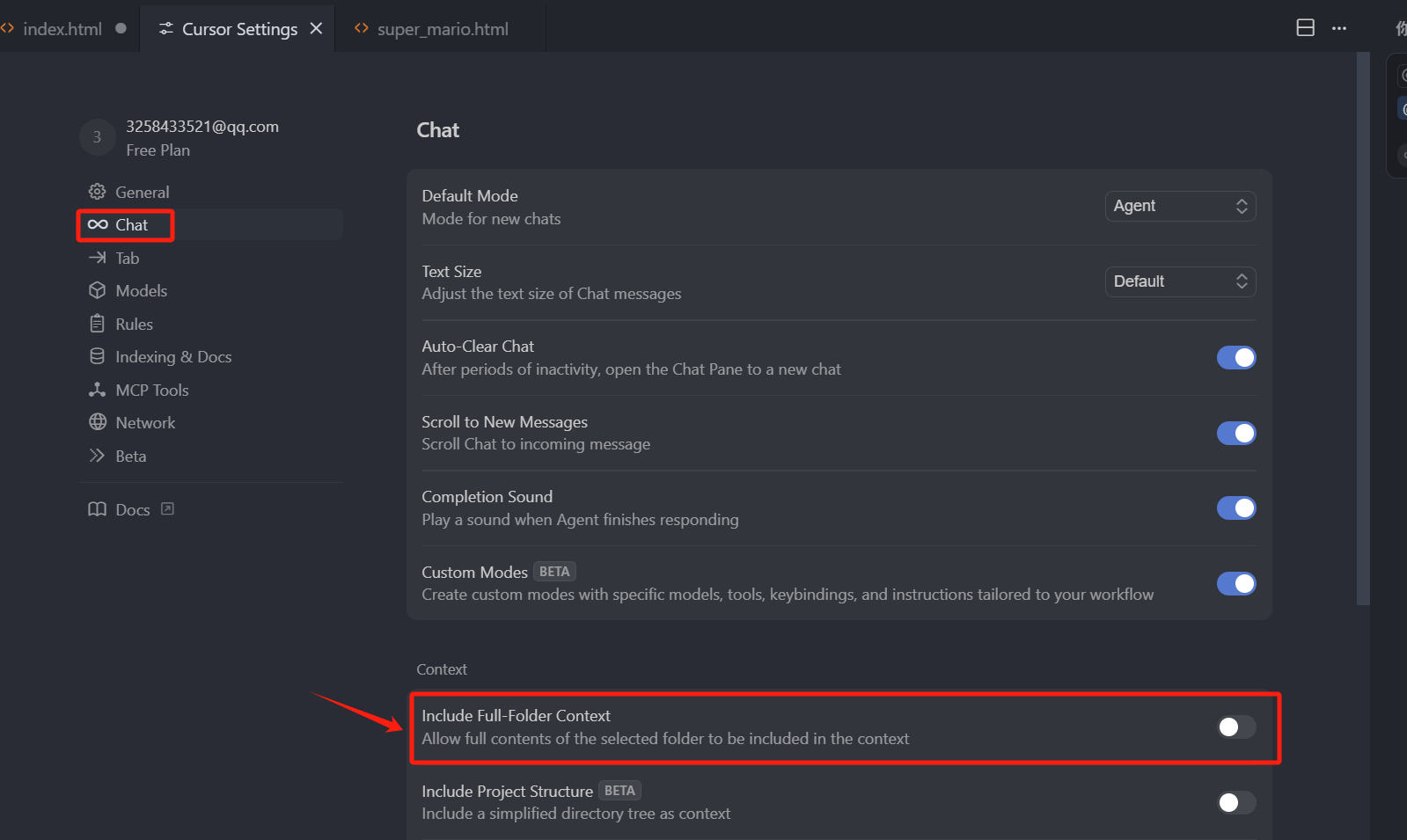
这是一个什么功能呢,如果你不开这个选项,选中文件夹时,文件夹仅仅是作为一个引用,在 Cursor 回答问题时,如果需要用到文件夹下的文件,会先根据引用去读取,把读取到的内容给到上下文。
当我们打开这个选项时,我们再选中一个文件夹时,Cursor 会直接把这个选中的文件夹内的所有内容,直接加到上下文中,如果你的文件夹中内容很多,超出了模型的上下文限制,那选中的文件夹,最后有一个黄色的警告,Cursor 会在上下文限制内压缩你的内容,整个文件夹内容直接加到上下文,上下文太大并不是一件好事,特别是使用 Max 模式的话,是按照 Token 计费,那开启了这个选项之后,我只能说是看代码多还是钱多了,所以我们还是关掉它。
3.1.2 @code
然后是 @code 指令,它可以让我们直接选中文件夹中的一些代码块,纳入上下文,

使用它的前提是,首先我们要打开一个代码文件,只有我们打开的这些代码文件,才会自动检索分割文件代码块儿。
3.1.3 @Docs
然后是 @Docs,它可以选中我们提前预设好的一些文档,作为上下文的一部分,
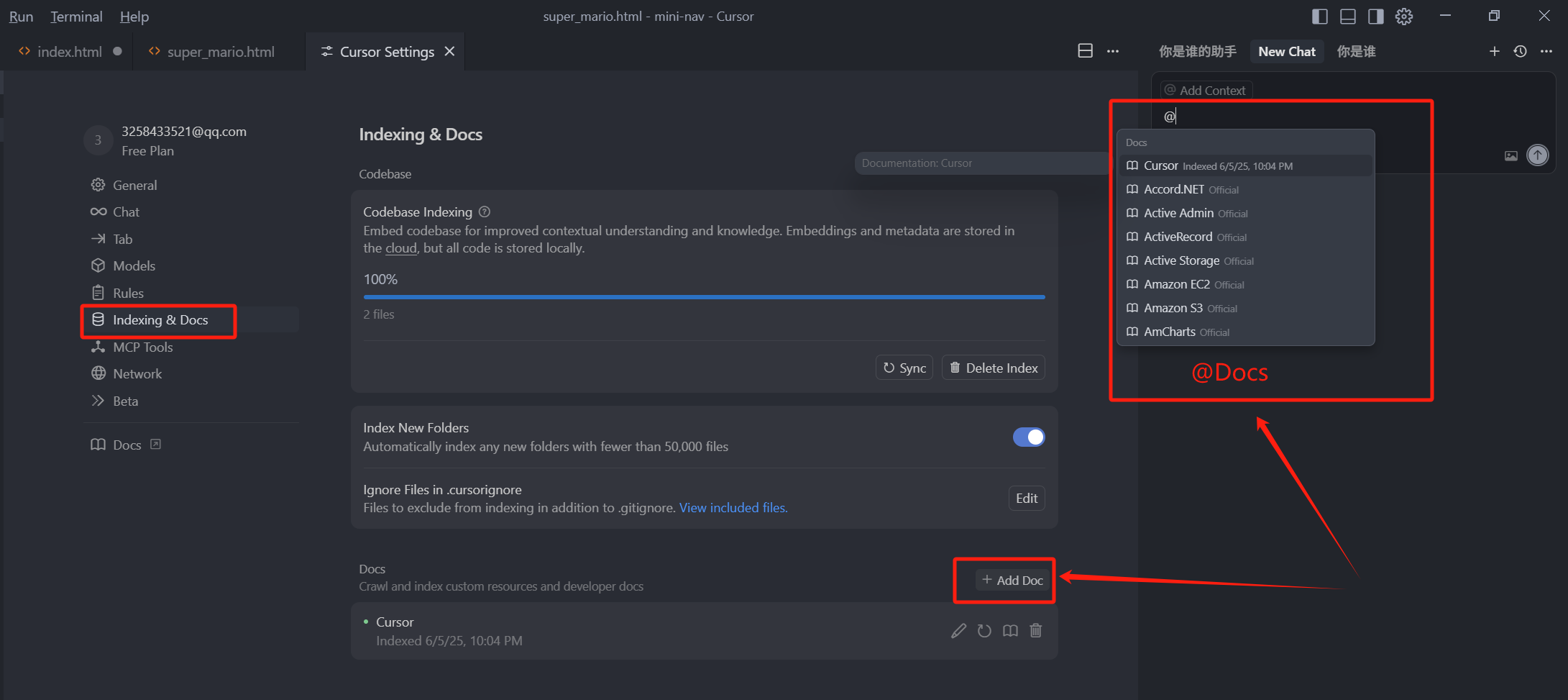
添加 Docs 的话,我们需要点击右上角的设置,然后找到 Indexing & Docs 类目,点击右侧的 Add Doc,我们可以输入一个 URL,回车,就可以添加一个在线的文档,
那上期 cursor 视频在讲这个功能时,有说到,在添加的文档链接中,这个 URL 如果以斜杠结尾(比如 https://docs.cursor.com/),Cursor 会自动抓取这个链接文档中的所有子页面;如果没有以斜杠结尾(比如 https://docs.cursor.com),只会抓取链接所在的这一个文档页面。
那在新版本中,无论是否以斜杠结尾,Cursor 都会自动帮我们抓取相关的子页面,这也是一个合理的更改,因为 Docs 这个功能,比较适合我们添加某些官方文档,或者是接口文档、需求文档这种在线的大型文档。
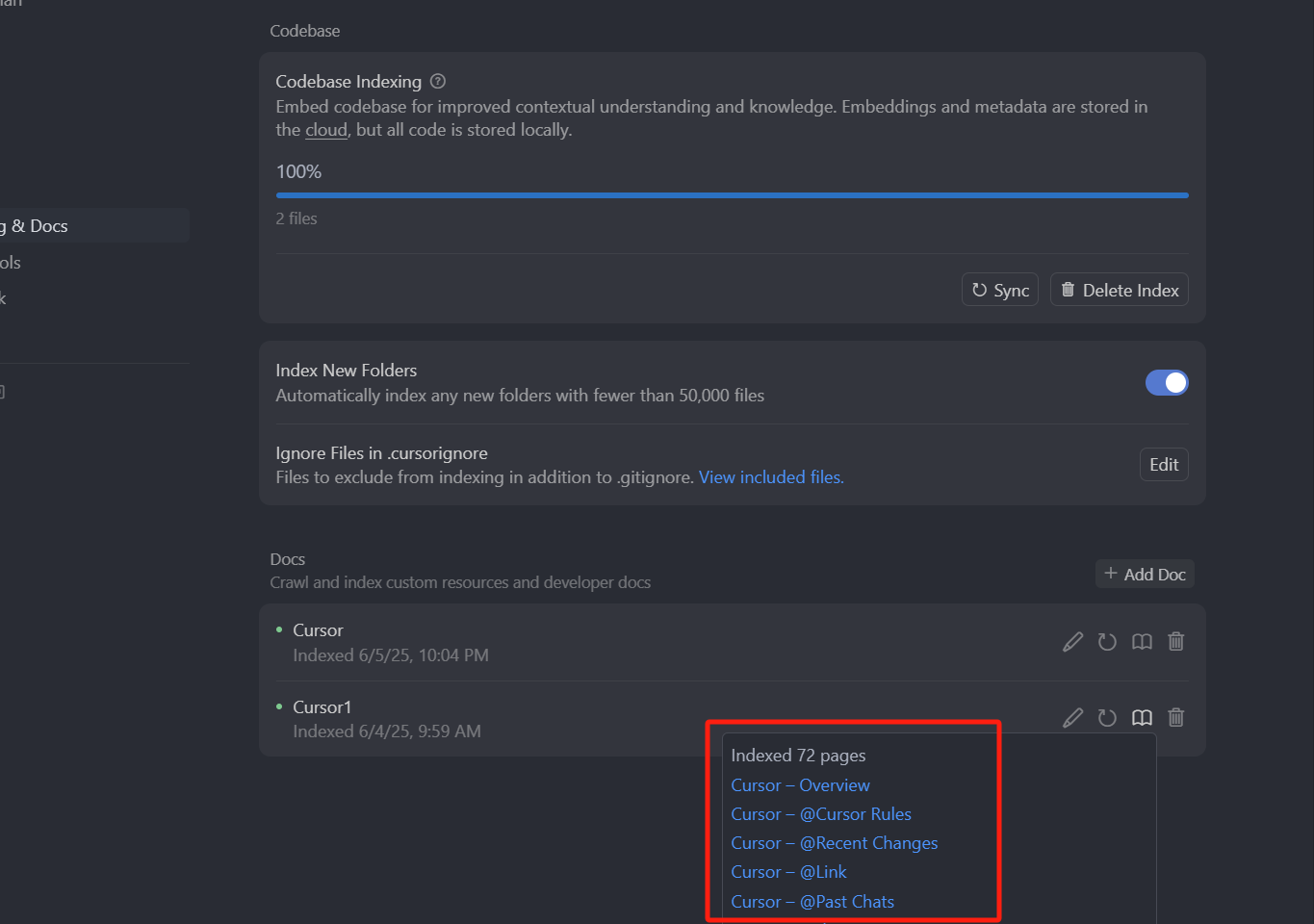
我们回车,点击确认,可以看到我们没有以斜杠结尾,它也帮我们抓取了 72 个页面。
如果我们单纯的想让 Cursor,解析一个链接中的内容作为上下文,其实并不需要用 Docs 这个功能,我们可以直接在输入框中,粘贴一个链接就可以。
那老版本中是有 @Link 指令的,新版本中移除了这个指令的入口,但是并没有移除这个 Link 的功能,毕竟链接一般是直接复制粘贴的,粘贴后就可以自动添加一个 Link 解析,所以去掉这个 @Link 的指令也合理,需要注意一点的是,如果粘贴链接时,链接是纯文本,比如这种。
这种情况下,Cursor 并不能为我们解析链接中的内容,只有粘贴链接后,链接转换成了这种以 @ 开头的链接块儿,才是识别到链接的状态,之后在发送问题时,会先解析链接,抓取到内容,再结合我们输入的内容给我们结果。
否则的话,一个纯链接文本发送过去,就只是一个文本,并不会解析链接,接着我们再说下一个功能,
3.1.4 @Git
这个指令还是和之前一样没有改变,那这个 demo 因为没有使用 git,所以不演示了。
简单说一下,如果我们使用 Git管理项目代码,那么你可以通过 @Git 指令,来选中历史的提交记录作为上下文,比如我们可以选中两个历史提交记录,让 Cursor 对比差异,或者是选中某个历史提交,询问一下更改的细节等等等等,就不过多赘述了。
3.1.5 @Web
然后我们再来说 @Web,这个也没什么说的,和之前一样,只要我们在输入框中选择了 @Web 指令,Cursor 就会先拿我们输入的内容,去网络上搜索一些结果,然后基于这些结果再回答我们的问题,Ask、Agent 模式都会自主调用这个工具,注意是自主调用,模型觉得需要调用这个工具了,它才会调用,并不是一定都会调用,所以大家如果很明确的,想让 Cursor 先去搜索,再根据结果给出答案,就需要我们手动输入这个指令就好了。
Manual 模式由于不会自主调用 @Web,所以我们如果想要在这个模式中,让 Cursor 先搜索网络的话,就要手动带上这个指令。
3.1.6 @Linter Errors,
这个指令其实一直以来都很少用到,我们之前也介绍过这个功能。
带上它之后,大模型在回答中修改代码以后,如果修改的代码产生 Lint 语法错误,或者是警告,Cursor 就会自动捕获,并且尝试去修复它,为什么很少用到,原因很简单,Agent 模式默认就会修复 Lint 错误,除非你手动在设置中关闭 Lint 检测。
但是,如果你在设置中关闭了这个选项的话,输入指令也是没有用的,而 Ask 模式不会编辑我们的代码,也就不会产生 Lint 错误,所以其实算下来,只有在 Manual 模式中,手动去使用这个指令才会生效。
3.2 新增的 Symbol 指令
旧的 Symbol 指令就介绍完了,我们再来介绍一下 0.44 版本后面,陆续新增的一些 Symbol 指令,如果硬要让我把这些新增的 Symbol 指令,做一个优先级排序,那么 Past Chats 无疑是最重要的一个。
3.2.1 @Past Chats
这个指令,可以让我们选择一个历史的 Chat,选中之后,Cursor 会自动总结这个 Chat 上下文的内容,把总结的内容带进这个新的上下文,相信只是这么一说,聪明的朋友们,就可以意识到它的重要性,一直以来,由于大模型有上下文长度限制,所以我们在一个 Chat 上下文中,必然就聊不了很长,因为一旦上下文过长,模型的答复质量会越来越低,因为会受到上下文内容的影响,所以我们要不停的手动新建 Chat,来规避这个问题,但是一旦新建了 Chat,之前 Chat 的上下文,我们调教模型的一些内容,或者是一些连续性的问题,信息就丢失了。
有了这个指令之后,我们再新开一个 Chat 的上下文时,如果想让模型了解之前的上下文的一些内容,我们可以直接通过这个指令,去选中那个 Chat 记录就可以了,当然这个功能,并不是完整的把旧的上下文,给到新的上下文,而是做了个 Summary,也就是摘要或者说总结,给到新的上下文,这样就在一定程度上,把旧上下文中的冗余内容去掉,只保留核心内容给到新的上下文。
就比如我们在这个 Chat 窗口中,就可以选中之前的一个记录,然后再输入问题,那它就会知道在之前这个上下文中,主要聊了什么
3.2.2 @Recent Changes
再来介绍一个也很不错的,新的 Symbol 指令,Recent Changes。
看名字就可以看出个大概:最近修改,使用它之后,Cursor 会引用最近修改的代码,作为 AI 聊天的上下文,其实我们在使用 Cursor 时,Cursor 会自动跟踪代码库的最近更改,并且存入缓存,而 Recent Changes 指令,允许我们将这些最近的修改,作为上下文传递,这其实也是社区中激烈讨论后产生的一个功能,因为很多需求让 Cursor 实现时,可能要经历很多次修改,如果 Cursor 在某次修改中修改的不对,我们可以拒绝接受修改的代码。
但是有这样一种情况,我问了一个问题,Cursor 帮我修改了代码,但是 Cursor 修改后的代码并不全对,我们需要基于上一次修改的内容,再做延伸,或者说限定上次修改的内容范围,让 Cursor 在这个上次修改的代码范围内,再做修改,这个时候我们就可以使用到 Recent Changes 这个指令。或者更粗暴一些,当你忘记了,上次 Cursor 帮你修改了什么代码,我们就可以选中 Recent Changes 指令,然后输入最近修改了啥,回车,你就可以得到之前修改了什么,也是很实用的一个 Symbol 指令。
3.2.3 @Terminals
接下来我们来到终端这里,那如果不知道怎么打开的话,我们可以点击右上角的这个切换面板,就可以打开终端。
当然你也可以直接,CMD+J(Win:Ctrl+J)快捷键直接打开,我们先输入一个错误的命令回车。

在之前,如果我们执行一个终端命令出错了,我们需要选中这块出错的信息,我们可以直接复制这个错误信息,然后粘贴在聊天上下文中,也可以直接点击右侧的 Add to Chat,一键把错误信息粘贴到聊天上下文中,其实还是有点复杂的,毕竟需要手动选中。
在新版本中,我们就可以通过 @Terminals,直接选中一个终端窗口。
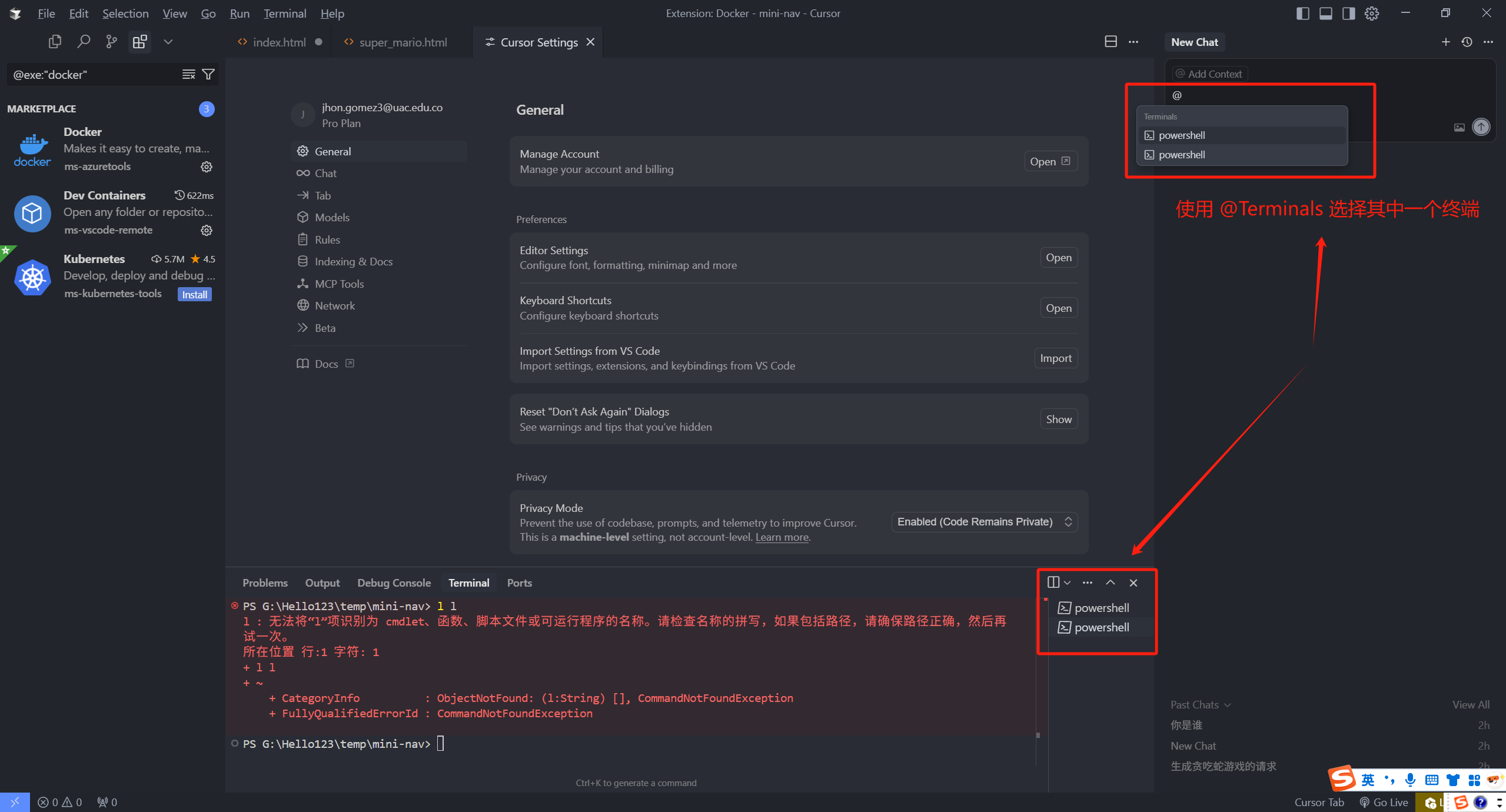
我们可以直接输入 @ 选中 Terminals,直接选中这个终端,然后输入“这个错误是什么问题”回车,
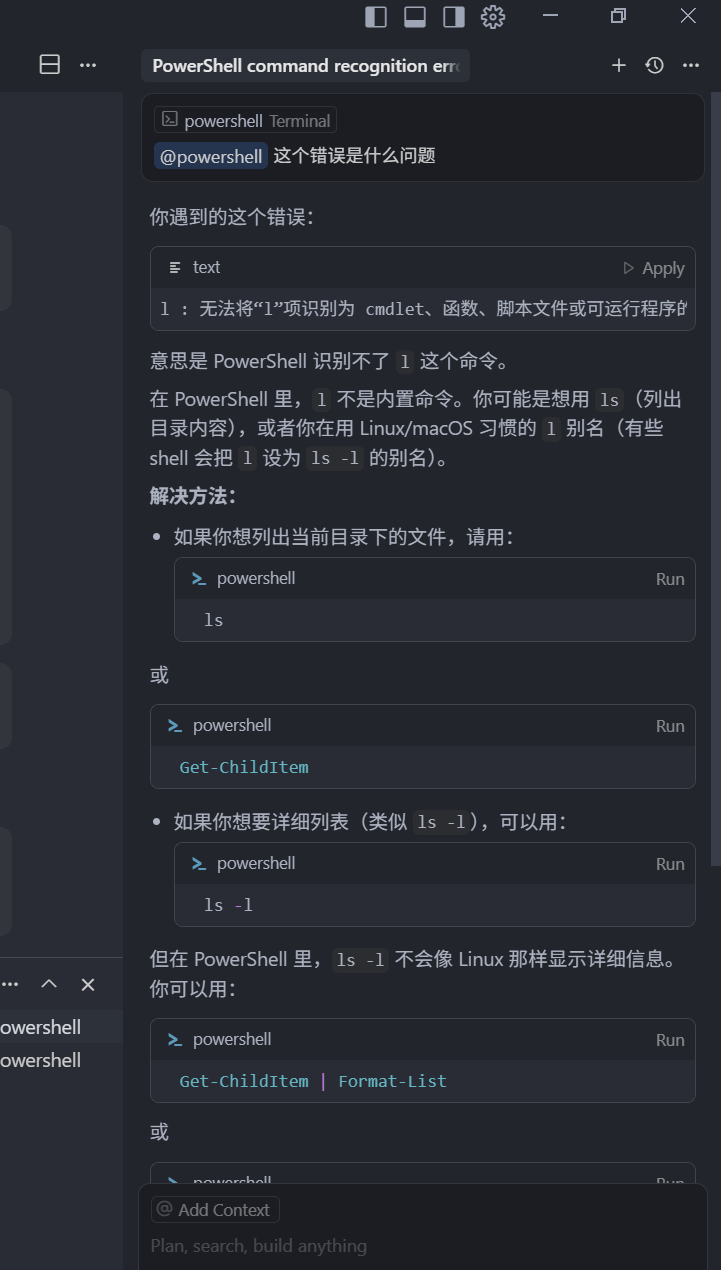
这个指令可以让我们把视线,始终聚焦到 Chat 输入框,通过输入框 Symbol 指令,快捷的带上附加信息,以解决大部分场景下的问题,而不需要我们直接再去终端,复制一些信息粘贴到上下文中。
3.2.4 @Cursor Rules
最后我们再来说 @Cursor Rules 指令。
那由于我们还没有介绍 Cursor Rules 这个功能,所以我这里简单提一下,后面还会详细介绍这个功能的使用,以及技巧。
在 Cursor 0.46 版本以后,Cursor Rules 就支持了一个项目设置多个 rules 规则,在 Ask、Agent 模式中,Cursor 会自动匹配应用我们设置的规则,但是 Manual 模式并不会应用规则,如果我们想在 Manual 模式中,使用某个规则,我们就可以通过手动输入 @Cursor Rules,然后回车。
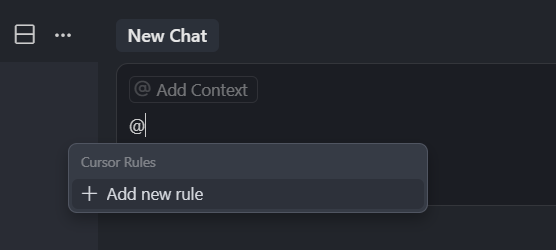
然后就可以选中列表中的一个 rules(我这里还没有添加 cursor rule),把它纳入到上下文,让 Cursor 知道你要遵循这个规则,给我生成答案,除此之外,在 Ask、Agent 模式中,虽然可以自主调用,但是不可控的因素会很多,所以,如果我们在这两种模式中问问题时,明确的知道它应该遵循哪个 Rules,手动通过 @Cursor Rules,添加这个 rules 到上下文是聪明的做法,
这块儿如果听不懂也没关系,因为我们后面会有很长一段内容聊 Cursor Rules。
上面就是 0.44 版本到目前最新版本中,新增的所有 Symbol 指令,介绍完旧的新的,我们再来介绍一下被移除的 Symbol 指令。
3.2.5 @Codebase
那说到被移除的 Symbol 指令,首当其冲的,肯定就是 @Codebase 这个指令,不过之前内容我们也有介绍过,Codebase 功能还在,只是转成了自主调用,手动 @Codebase 这个指令略显鸡肋。
有的朋友会问,这个指令还可以在 Manual 模式中调用啊,为什么要去掉,其实原因很简单,Manual 是手动模式,它现在的定义就是,只根据用户的指令去做事情,完全受控于用户,做事情的颗粒度也很小,因为我们需要明确的告诉模型,你要修改什么文件,这种场景下,@Codebase 这个匹配语义相关文件的功能,和 Manual 模式理念上就冲突了,纯手动的模式下,这个功能就略显鸡肋。
3.2.6 @Link
然后就是 @Link 这个指令,其实只是去掉了手动选中这个指令的入口,但是功能并没有删除,为什么删除这个入口,其实很简单,因为即使在老版本中,我们也不怎么会用到这个指令入口,而是直接粘贴一个链接到输入框,来使用这个功能,复制粘贴它不省事吗,所以没有必要手动输入@Link,有了也不用,但是链接解析这个功能是要有的,那如果你不想让模型解析链接,要把链接作为文本给到 AI 模型,也很简单,复制链接的时候,前面加几个文字。
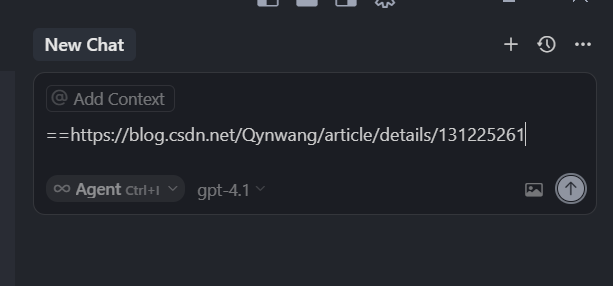
比如这样粘贴进来,链接就不会转成 Link 块儿。
3.2.7 @Notepad
最后我们再说 @Notepad 这个指令,大家可以直接略过 Notepad 这个指令的学习,因为这是一个即将删除的功能,无需了解,看过上一期 Cursor 视频的朋友,可以听一下Notepad 这个功能,其实一直以来都是 Beta 版本,到目前为止,虽然去掉了这个 Symbol 指令,但这个功能依然还在,只不过这个功能的入口隐藏的比较深(工作区面板,点击右键会出现),不出意外的话,未来会被移除掉。
那最开始这个功能的由来,是因为旧版本,Chat、Composer 模式时,这两种模式的上下文内容不同步,为了使上下文内容能够同步,或者说,为了能够重复的使用一些内容作为上下文,就有了这么一个记事本的功能。
我们可以在一个项目中,使用 Notepad 功能创建多个记事本,把需求上下文添加到 Notepad 的记事本中,在 AI 聊天框中要使用这个上下文,直接通过 @Notepad 指令,选中某个记事本,就可以把记事本中的内容带进上下文,但是它有很大的缺陷,我们创建的记事本,并不会存储在我们的项目文件中,而是作为项目的缓存去存储的,这样的话,一旦换个设备,或者是多人协同开发的时候,Notepad 就没有了记录。
当然,并不是说这个记录重复使用的内容,或者是统一记录文档的需求没有用,而是 Notepad 本身的功能相对鸡肋一些,因为我们可以直接在项目根目录下,创建一个文件夹,我们自己或者是一个 Team 内,约定这个文件夹使用 Markdown 格式文件,专门存放一些通用型的文档也可以达到这个目的,使用时直接使用 @Files 指令,去选中某个文档文件就可以了。
而且,由于是直接在项目中创建的文件夹,这个文件夹下的文件和代码文件,是一样保存在项目中的,也不会丢失,再加上新版本中的 Ask、Manual、Agent 三种模式,可以在一个 Chat 的上下文中随意切换,记录通用上下文用作模式之间同步的需求也就没有了。
新版本中还加了很多类似 @Past Chats(历史 Chat 总结)、@Recent Changes (最近更改)这种辅助功能,导致 Notepad 这个功能变得十分鸡肋,所以它即将被干掉,不要再使用这个功能了。
当然约定一个文件夹,作为一个专门存放用于 AI 问答的项目文档目录,还是有必要的,这一点,我们在后面介绍技巧时还会聊到,这里就不过多赘述了。
3.2.8 # 指令
接着我们要聊一个,大家可能都不太知道的指令,# 号指令,我们直接演示一下.
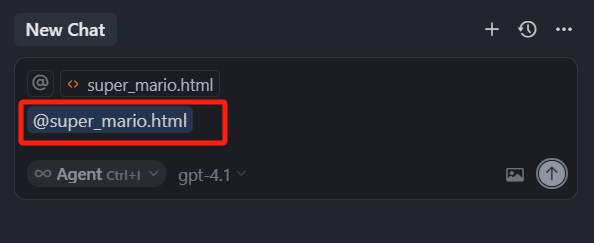
我们先使用 @File 指令,去选中一个文件,可以看到,其实输入框中,会有一个 @ 开头的文件名的块儿(@super_mario.html ),它表示的意思是,这个文件内容被添加到上下文,也就是这个文件中的所有的代码,都会作为上下文的一部分,大家再仔细看会发现,当我们使用 @ 符号选中一个文件时,输入框上方也会有一个文件的标记。
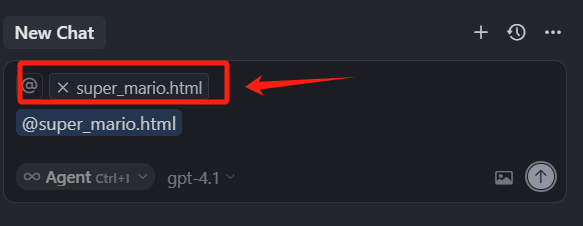
这个标记是为了告诉 Cursor,这次聊天要聚焦在这个文件,当然我们可以悬浮到这个标记上,点击删除就可以删除它,但是删除之后,我们选中的文件块也被删除了。
所以 @File 添加文件时,会默认添加一个聚焦的标记,并且 @File 选中文件的指令,是可以在我们输入的问题描述中,任意位置去添加的,可以作为问题描述中,根据语义指定的文件,比如你先去操作这个文件,然后使用 @Files & Folders 选中一个文件,并描述怎么操作这个文件,然后需要再去处理那个文件,那你就再选中一个文件@Files & Folders 并描述怎么处理那个文件。
而我们现在要说的#号指令,在用它添加一个文件时,其实就是添加了一个让 Cursor 聚焦到这个文件上的标记。
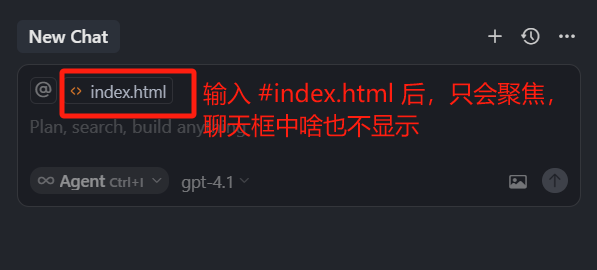
它和 @File 指令不同的是,聚焦选中的文件 ,Cursor 并不会先解析文件作为上下文,只是单纯的告诉 Cursor,你在回答时应该聚焦在这些文件上,至于要不要解析它,模型可以根据问题自己看着办。
应用场景:如果我们想让 Cursor 在回复时,在一定的范围内去做修改,就可以使用#号指令,选中我们想让 Cursor 聚焦的文件,一般情况下,当我们打开一个代码文件,然后再新开一个上下文时,这个文件聚焦会默认添加到当前的聊天上下文中。
这里还要介绍的一个概念是:当前活动的页面。
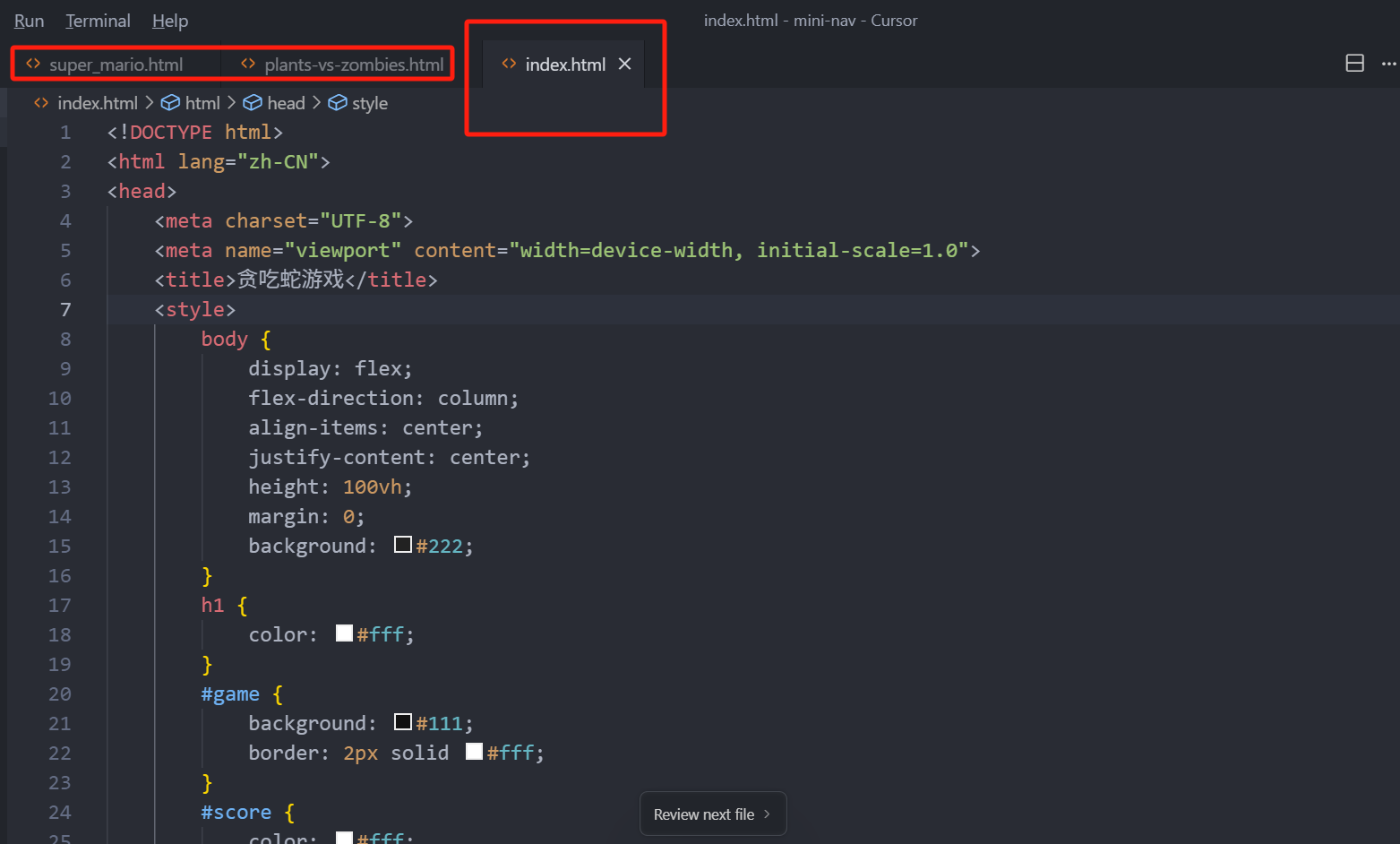
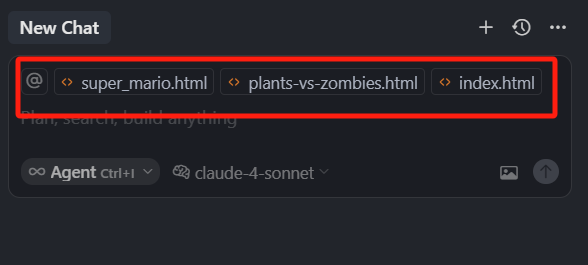
我们现在打开了 3 个文件,但是我当前的窗口在 index.html 上,那其实这个文件就是当前活动的页面,而这个 super_mario.html 和 plants-vs-zombies.html 这两个文件也已经打开了,但是他们是非活动页面,
这三个都是打开的文件,但是只有当前窗口是活动的。这个概念大家要理解。
3.2.9 斜杠(/)指令
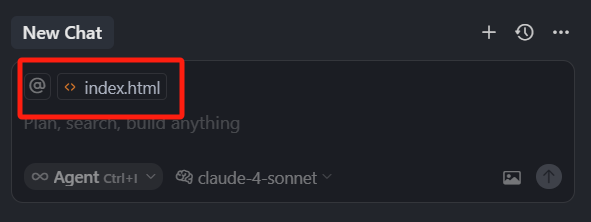
我们最后还要介绍一个特殊的指令:斜杠(/)指令,如果我们快捷的想要把打开的文件中,并且是当前活动窗口的文件,添加到上下文聚焦选项,我们就可以使用 Active Files to context,
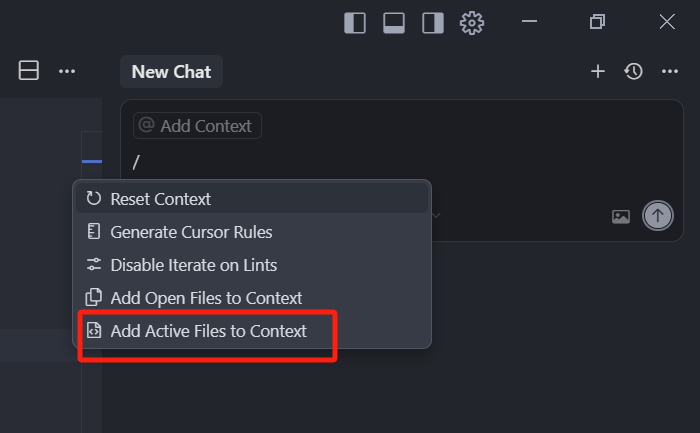
点击,我们就会看到,index.html 已经被我们添加进去了.
再次打开斜杠指令,那如果我们想要一键,把所有打开的标签文件,都添加到上下文聚焦项,我们可以直接选中,斜杠菜单中的 Add Open Files to context。
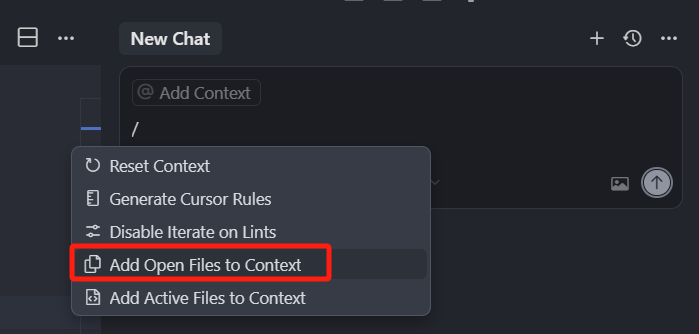
选中就可以看到,我们当前打开的 3 个文件,都已经到了上下文的聚焦列表中。
那如果我们想要一键重置这些聚焦项,我们就可以选中 Reset context。
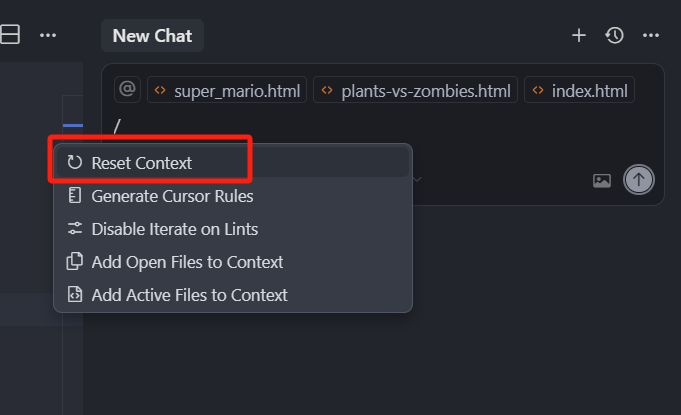
可以看到,当前上下文的聚焦项,就只剩了 index.html 这一个文件,这个功能是重置上下文。
我们也可以直接通过斜杠指令中的 Disable iterate on Lints,去禁用掉 Lint 错误的迭代
当然我们也可以再次选中就又打开了
那 Lint 功能我们之前介绍过,就不过多赘述了,当然这都是一些小功能,那最最重要的就是这个 Generate Cursor Rules
我们可以选中它,然后输入一些需求,让 Cursor 帮我们生成一个 Cursor Rules 文件,大家只需要记住,这个 Generate Cursor Rules 功能在斜杠菜单里能找到,后面我们还会细讲这块。
其实我们可以看到,斜杠菜单中的所有功能项,都是一些功能性的快捷操作。
以上就是新版本中,支持的所有的 Symbol 指令了,大家要牢记它们的作用,后面我们还会介绍到,在开发中使用它们的技巧。
四 MCP
那接下来我们介绍 Cursor 中的 MCP 功能,在介绍这个功能之前,还是要先给大家科普一下什么是 MCP,MCP 全称叫做 Model Context Protocol,它是一个开放性的模型上下文协议,它标准化了应用程序,如何向大语言模型,提供上下文和工具的方式,它的作用解释起来就一句话,让大模型可以通过一个统一的方式,去调用第三方的工具。
在大模型刚诞生的时候,人类和大模型的交互就是,你发送一个问题,大模型给你一个回答,假如我们问大模型:“查询北京明天的天气,基于明天的天气帮我规划一个日程”,完成这个任务的前提是,大模型需要知道明天的天气,显然大模型是不知道的,我们需要手动的先去查一下天气,然后粘贴进去天气,提示词就变成了:“北京明天雨夹雪伴随大风蓝色预警,帮我规划一下日程”。那这个时候,模型就会根据天气去做出回答,所以我们想要让大模型和外部数据信息交互,只能通过手动复制粘贴的方法,把外部数据粘贴给大模型。
这很麻烦,所以后来,模型厂商就搞了一个叫 Function calling 的东西,大模型可以通过 Function calling 接口,去调用外部的一些工具,来获取各种数据,再返回给模型。
但是 Function calling 有一个很大的缺点,每个大模型厂商,都定义了自己的 Function calling 接口,标准和要求都是不一样的,假如我开发了一个工具,想提供一些信息给大模型使用,那么针对各个大模型,比如 GPT、Gemini、Deepseek,我要先给 GPT 开发一个,再给 Gemini 开发一个,再给 Deepseek 开发一个,总而言之,只要大模型支持 Function calling,我想让这些大模型可以调用我的工具,我就要分别针对这些支持的大模型,开发对应的 Function calling 接口,这样,这些大模型才可以调用我这个工具。
而 MCP 就相当于做了一个统一的标准,我们只需要按照 MCP 标准规范,开发一个 MCP Server,那么所有支持 MCP client 的大模型,或者是集成了 MCP client 的产品,都可以去调用我这个工具。如果大家都认可并且遵循这个规范,那么第三方工具只需要按照标准规范,提供 MCP Server,就可以接入所有支持 MCP Client 的大模型,或者说产品,比如 cursor。
标准统一的情况下,MCP Server 可以预见的会越来越多,那只要有足够多的 MCP Server,理论上大模型可以调用一切,所以 MCP 异常火爆。
那针对 MCP Server,我们可以在本地启动一个 MCP Server 项目,通过标准输入输出,也就是 Stdio 模式,与我们要使用的,支持 MCP Client 的产品去通信。
我们也可以使用 SSE 的模式,直接输入一个 MCP Server 链接,以 HTTP 协议,与我们要支持的 MCP Client 产品通信。
而在 Cursor 0.45 版本以后,就集成了 MCP Client,所以我们可以直接在 Cursor 中,配置一些 MCP Server 来优化自己的工作流。
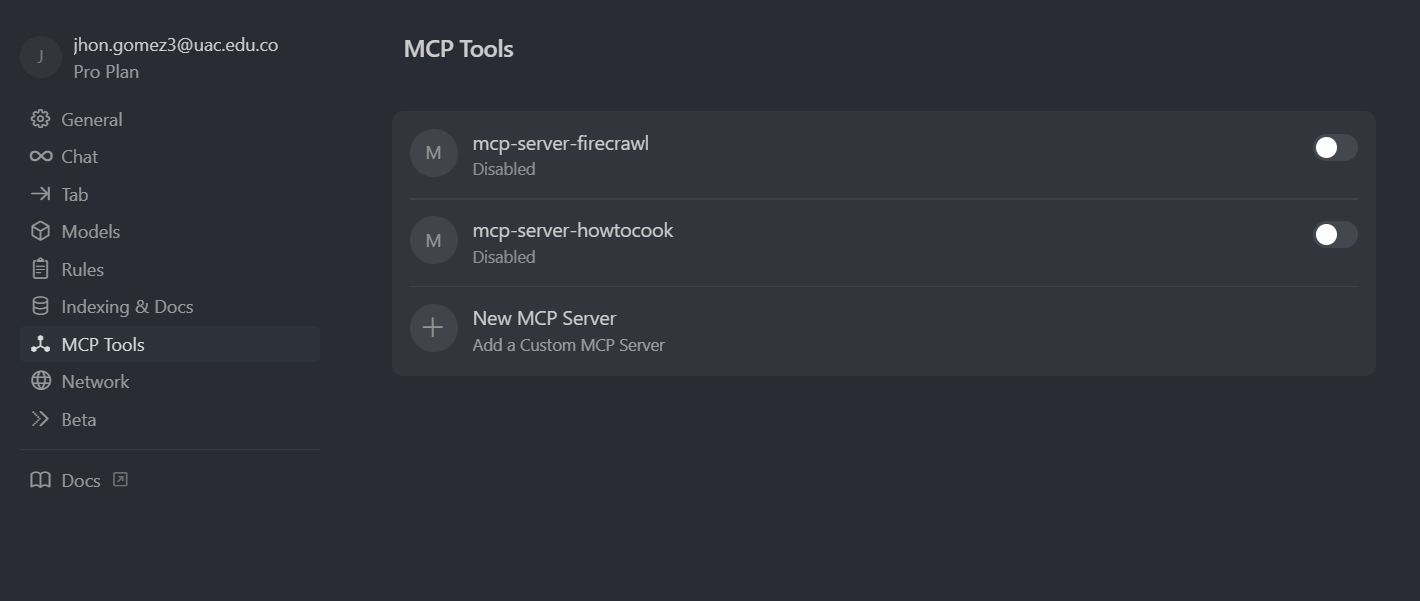
我们直接来做一个示例,我们先去配置一个 MCP Server,点击 Cursor 编辑器右上角设置,然后点击左侧的 MCP,右侧面板,就会展示我们配置的所有 MCP Server,目前是还没有配置,
我们点击 Add Custom MCP,就可以添加一个全局的 MCP Server,那点击 Add Custom MCP 之后,就进入到了全局 MCP Server 的配置文件,这是一个 JSON 文件,我们尝试添加一下,保存。
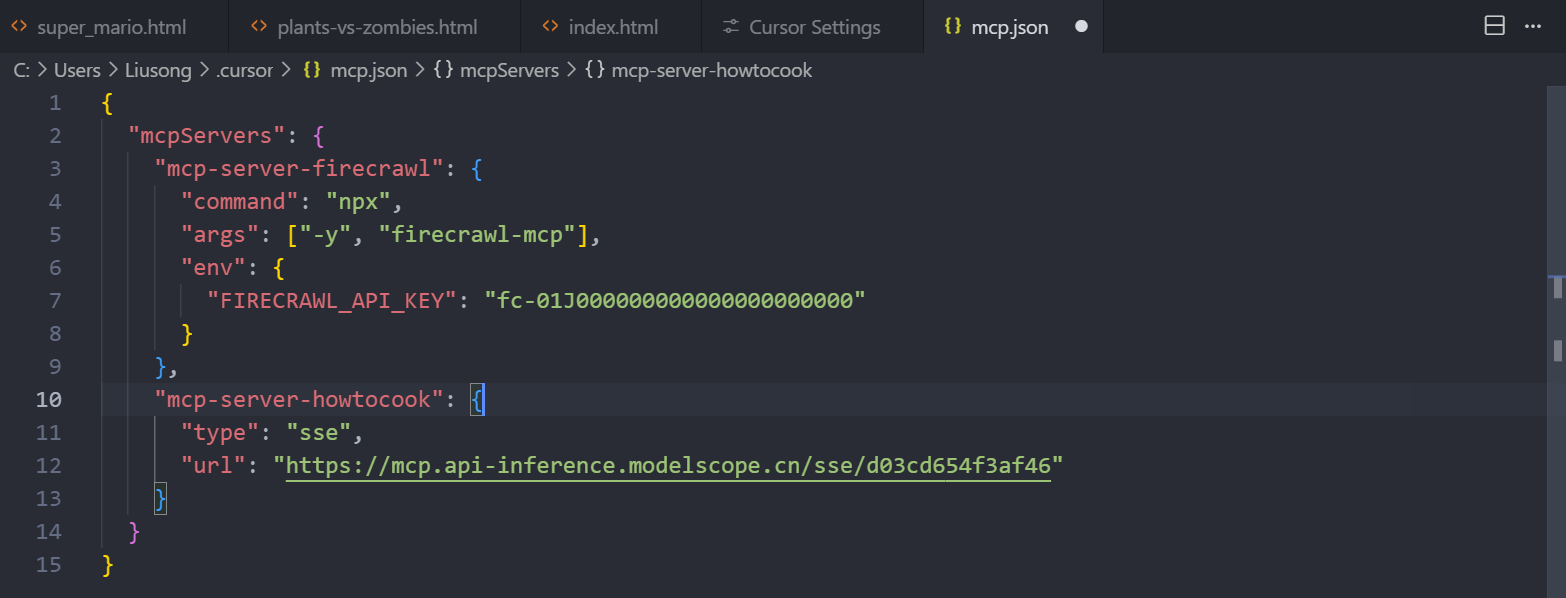
那这个配置中,我们使用 Stdio 和 SSE 模式,分别配置了一个 MCP Server,这里的 mcp-server-firecrawl 和 mcp-server-howtocook,是我给这两个 MCP Server 自定义的名字。
上面的 mcp-server-firecrawl,是一个集成 Firecrawl 能力的 MCP Server,Firecrawl 大家可以简单理解为,是用来抓取网页内容、格式化输出,或者搜索网络内容的一个工具,这个 MCP 我们使用的是 Stdio 模式,由于是 Stdio 模式,所以它其实是本地服务,也就是说 Cursor 会使用我配置的命令,在我本地启动一个 MCP Server 的服务来调用,而这个本地服务内部,会调用 firecrawl 这个工具的云服务,所以这里我配置了一个 Key(无需尝试,Key 是假的),那由于这个 MCP Server 走的是 Stdio 模式,Cursor 要运行我配置的命令,那比如我们这里配置的是 npx 命令,那我们本地就要有 npx 的环境,npx 是 npm 的命令,npm 又是 nodejs 的包管理器,所以我需要本地装好了 nodejs 环境才可以。
当然,这里不只是 nodejs 可以运行 MCP Server,像 Python 啊、Go 啊、C++ 都可以用,但是前提你要用哪种,就要装哪种的环境,这对普通用户来说,是一个非常痛苦的事情。
而下面的 mcp-server-howtocook,它是一个叫今天吃什么的 MCP Server,它可以帮助我们推荐菜谱、规划饮食,解决今天吃什么的世纪难题,这个 MCP Server 我用的是 SSE 的方式,这种方式就清爽了很多,因为它不需要我们本地有环境,直接走了一个 HTTPS 的链接,对小白来说是十分友好的。
但是话说回来,我们之所以能使用这种 SSE 的方式,完全是因为别人部署了这个 Server,我们直接连的别人部署好的 Server,现在很多做 MCP 广场的平台,都会把一些优秀的 MCP Server 部署好,让我们使用 SSE 的方式便捷接入,但是部署是消耗云资源的,所以,他们一般会把比较热门的 MCP Server 部署,很多新出或者是小众的 MCP Server,依然还是要通过 Stdio 模式去使用。
那我们保存之后,就可以回到设置页面去查看了,还是点击 MCP Tools
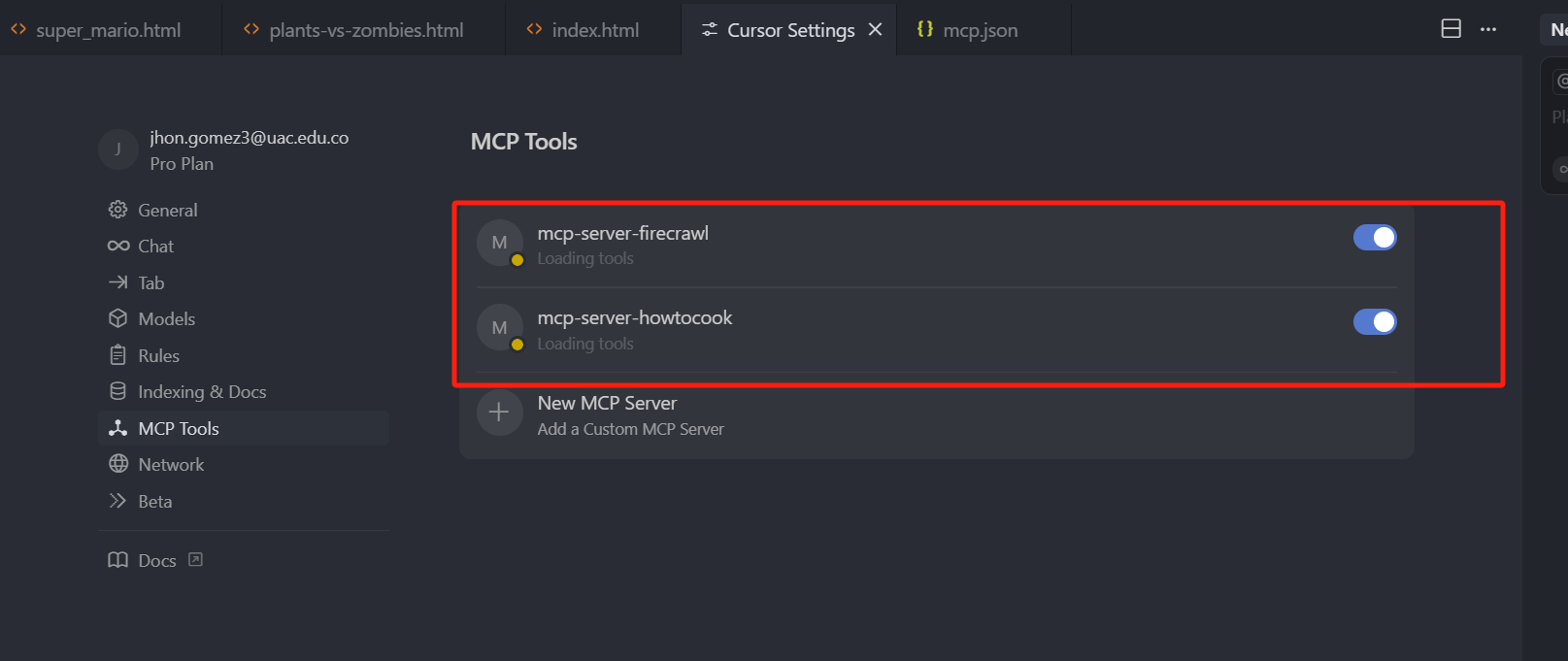
可以看到,MCP Server 列表中就已经有了,这里需要注意的是
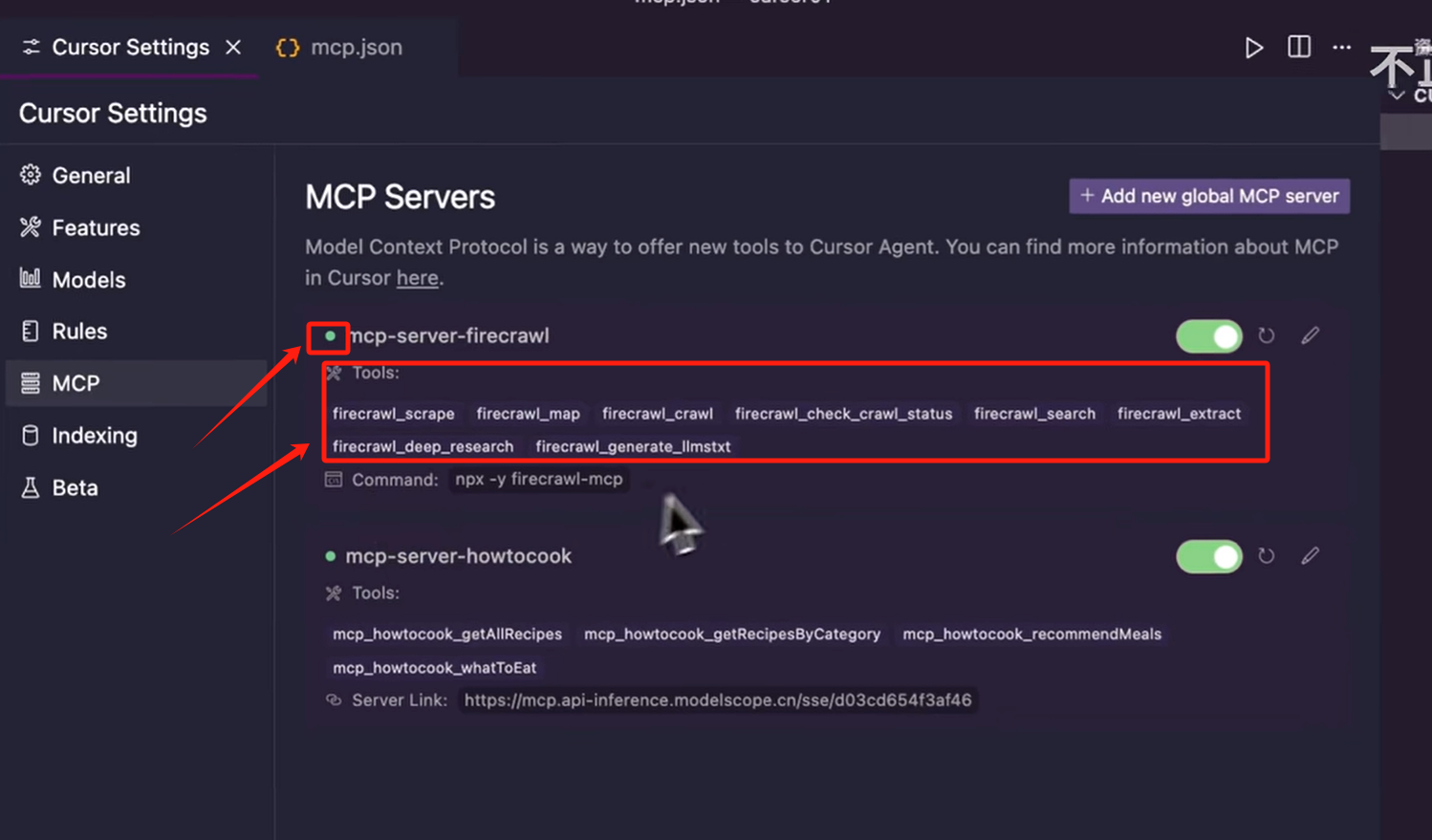
只有列表中的 MCP Server,名字前有个小绿点,并且名字下方,已经成功拉出了一堆 MCP Tool,这里面的每一个方法,我们称它为一个 Tool,当我们看到了小绿点,还有下 面已经拉出了 MCP 的 Tool,这个 MCP Server 才是一个可用的状态,如果你的 MCP Server 名字前方是黄色小点,代表还在尝试连接,红色小点代表连接失败。
那列表项的右侧也有一个开关,我们如果暂时不想使用这个 MCP Server,就可以把它禁用掉,再次使用就可以把它打开。
确保这两个 MCP Server 成功连接了之后,我们就可以尝试去使用一下了,我们来到 Chat 面板,输入一个爬取链接的提示词,回车。
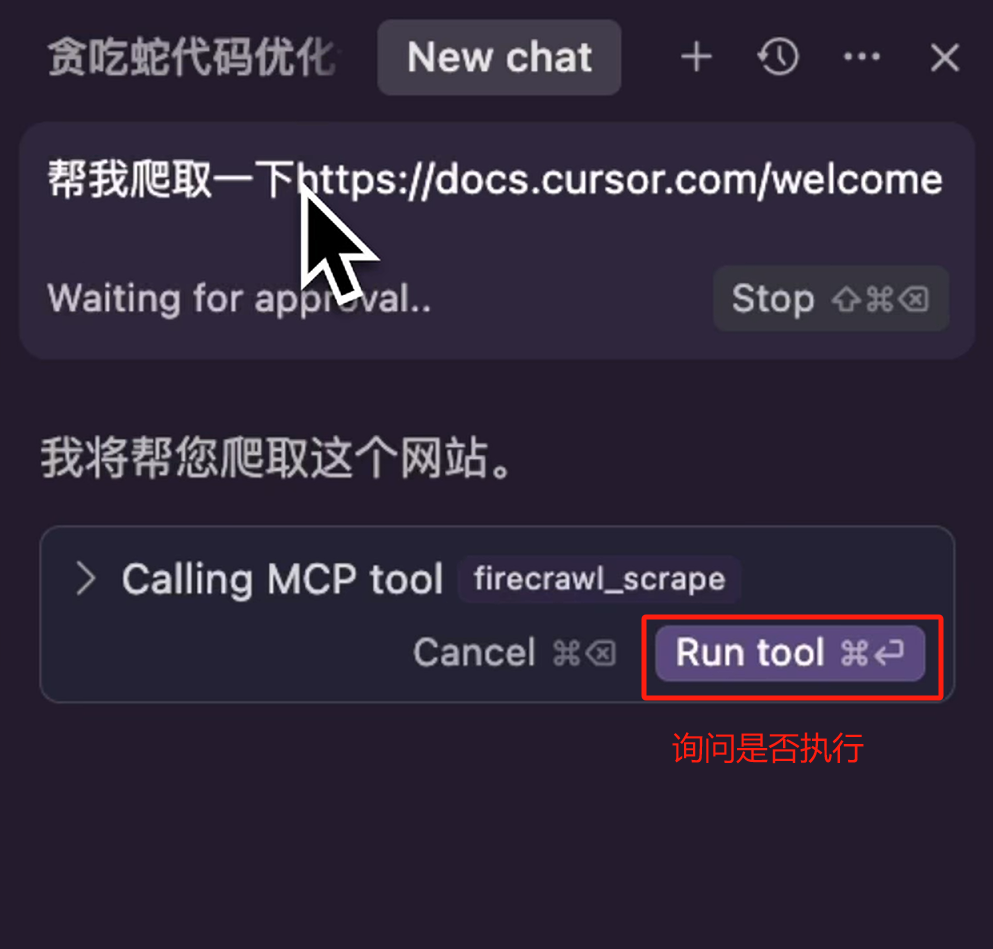
注意我们输入的这个链接是个纯文本,而不是一个 @Link 块儿,那由于我们让模型爬取一个链接。
刚好我的 Firecrawl MCP Server 中,有网页爬取的一个 Tool,所以 Cursor 就会自动匹配到,然后它就会向我们询问是否要运行这个 MCP Server Tool,调用的是这个MCP Server中的 firecrawl_scrape 方法,我们点击运行。

执行成功后,拿到结果再反馈给我们内容,我们也可以点击这个 MCP Server,来查看一下调用详情
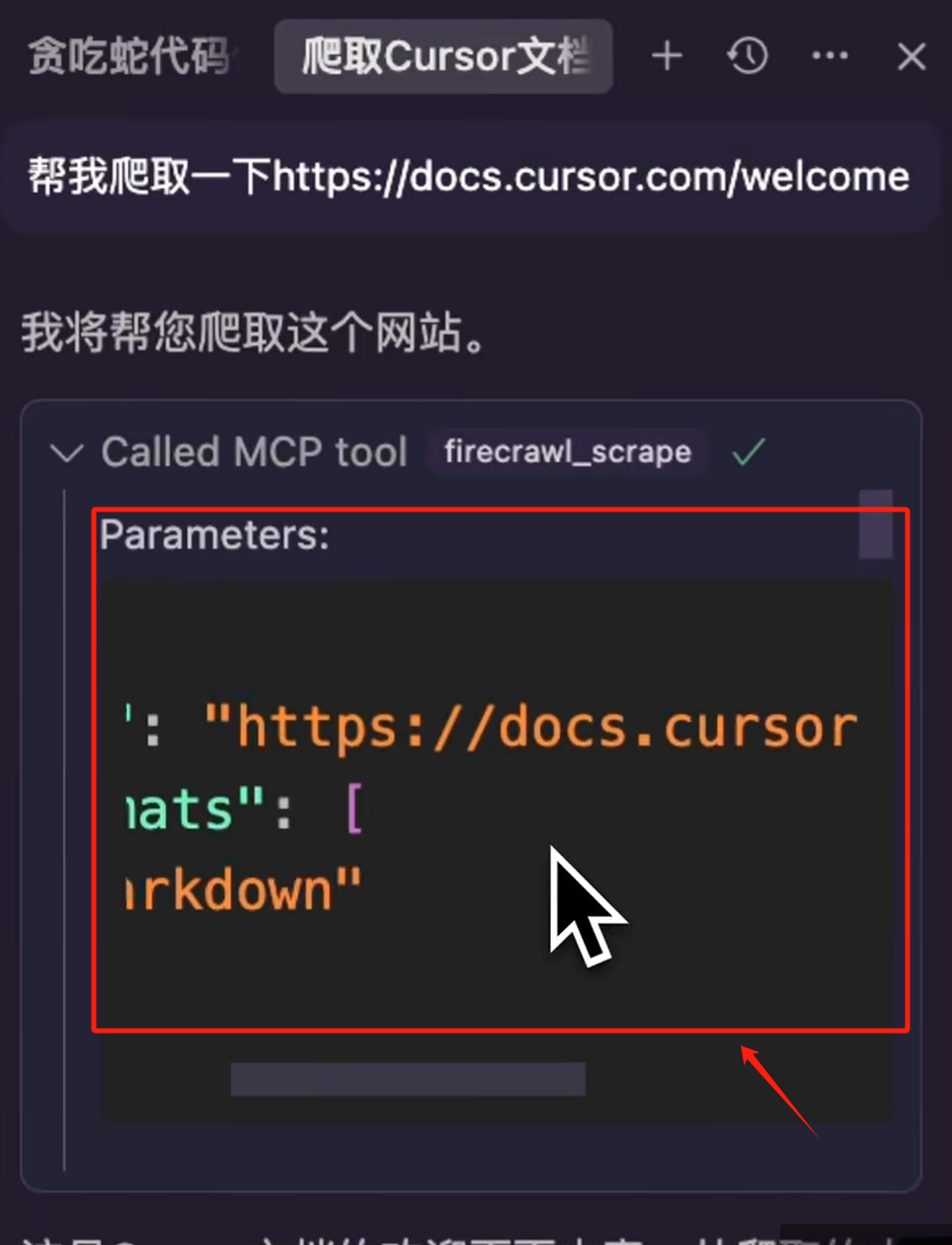
可以看到调用参数结果其实都有,Firecrawl 这个 MCP Server 中有很多 Tool,我们就不一一演示了。
当我们使用 Agent 模式发送一个问题时,只要我们输入的内容,与 MCP Server 中的 Tool 描述匹配,Server 就会自动触发 MCP 调用,并且询问我们是否执行,当然如果你打开了 Auto-run,也就是自动运行的选项,它会直接执行。
我们再来演示一下另外一个 MCP Server,新建一个 Chat,输入 “一个人早餐吃什么”,回车
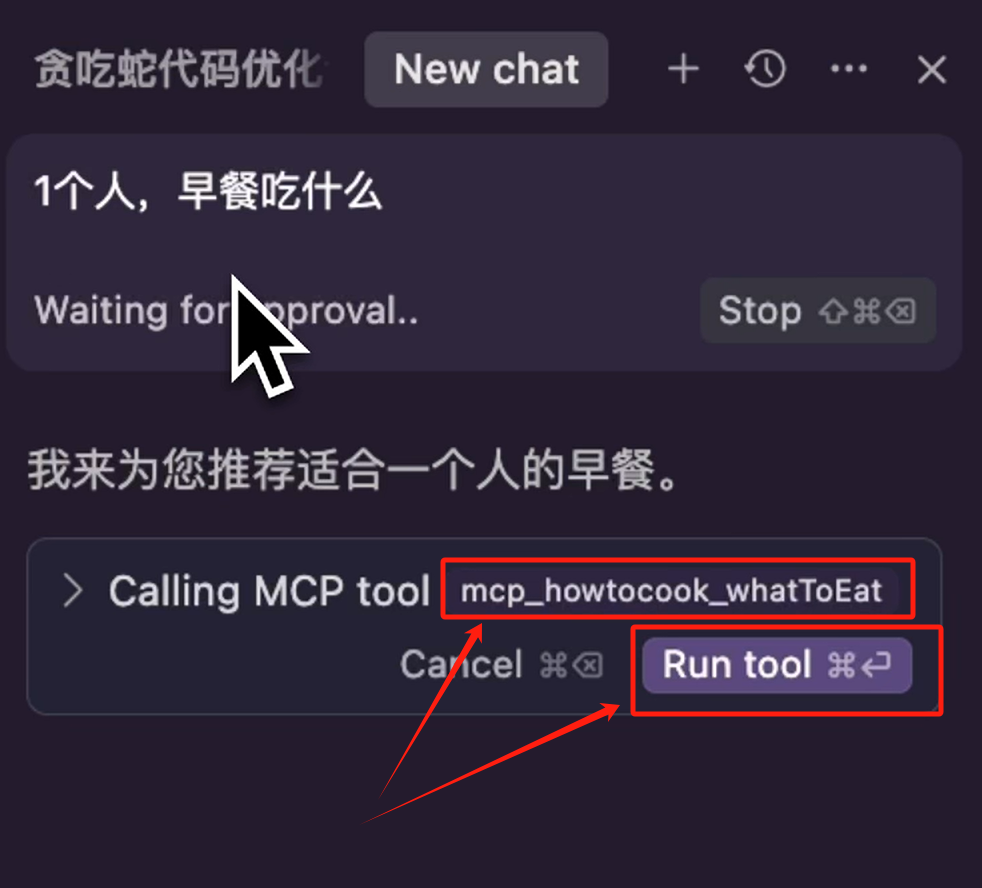
可以看到它会触发 “mcp-server-howtocook” 这个 MCP Server 中,一个叫 mcp_howtocook_whatToEat 的 Tool,我们点击运行,
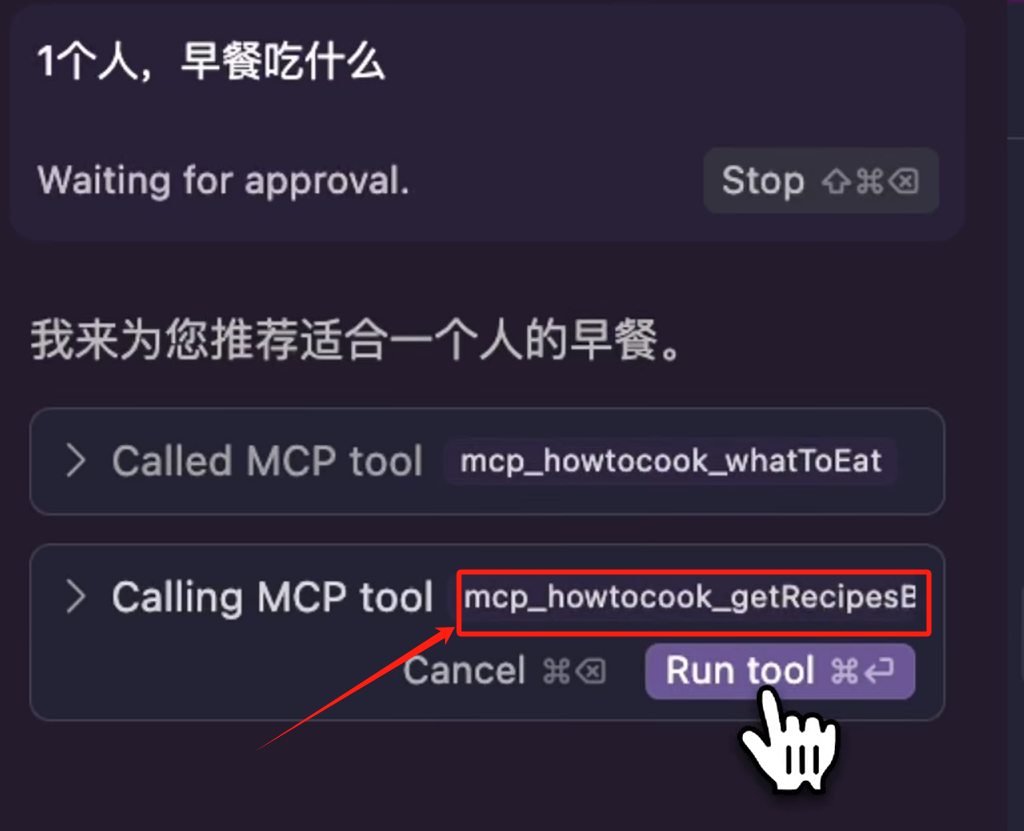
然后它又让我再次执行 MCP Server Tool,那这个 Tool是一个按类别来查询菜单的一个方法,我们再点击运行

结果就出来了,另外 我们在设置那里创建的,是一个全局的 MCP Server,也就是说,只要我们在全局 MCP Server 中,启用了某个 MCP Server,那么我们在 Agent 模式中的问答,只要能跟 MCP Server 中的某个 Tool 语义匹配,就会触发调用,这其实很不友好,因为可能我在某个项目中,想要使用几个 MCP Server,在另外一个项目中,又要使用另外几个 MCP Server,全都配置成全局的,项目中如果不想使用,还得手动去设置里面禁用这个 MCP Server,其他项目用的时候还要再开启,是比较麻烦的。
那针对这种情况,Cursor 也允许我们配置项目级的 MCP Server,也就是只在这个项目中使用,我们需要在项目的根目录下创建一个 .cursor 文件夹,然后在这个文件夹下,创建一个 mcp.json 的文件
这就是一个项目级的 MCP Server 的配置文件,和全局配置的书写方式是一致的,我们把全局的这个复制一下,然后删除掉全局的配置,保存,然后把之前全局的配置,粘贴到项目级 mcp.json 里面,保存之后我们再去设置里面查看 MCP.
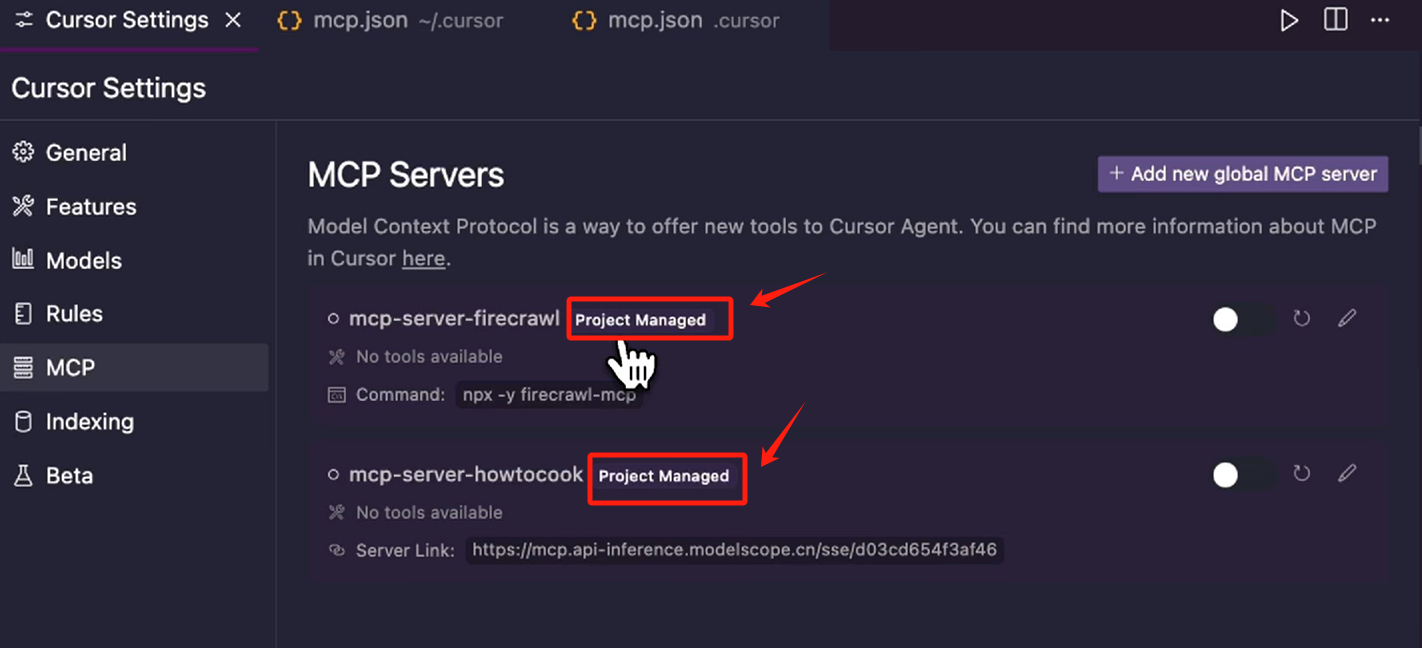
可以看到这两个 MCP Server 还是在的,他们的名字右侧,会展示一个 Project managed 的标识,标识这是一个项目级的 MCP Server,另外项 目级的 MCP Server 默认是禁用的,我们需要打开一下才可以用.
这就是在 Cursor 中 MCP 的使用,那如果大家想不到 MCP Server 功能的用武之地,也不要着急,关于 MCP 功能的思路以及玩法,后面还会聊到。
五 Cursor Rules
我们详细介绍一下 Cursor Rules 这个功能,注意 它非常重要,很多人并不是很关注 Cursor Rules,这是错误的,想玩好 Cursor,特别是做 AI 编程,Cursor Rules 不可或缺,就目前来看,Cursor Rules 将会是普通用户和高玩用户之间的分水岭,Rules 翻译过来就是规则的意思,其实我们也可以把它理解为大模型的系统提示词,什么是系统提示词,大家可以简单的理解为,我们写了一段文本,每次我们新开一个聊天上下文时,这段文本就会预置在这个新的上下文头部,当我们向 AI 模型发送一个问题描述时,这段文本就会作为前置背景,给到 AI 模型。
我们可以在系统提示词里,设置一些规则,比如把你需要使用中文回复,添加到系统提示词,那么后面这个聊天上下文中,模型所有的回答都会使用中文回复。
其实绝大多数模型厂商发布的模型,都会有一些内置的系统提示词,这些内置系统提示词,可以引导或者约束模型对用户的输出,而系统提示词在 Cursor 中被称为 Rules,也就是规则,在 Cursor 中支持全局规则和项目级规则。
5.1 添加规则
我们先来看一下全局规则,点击 Cursor 编辑器右上角的设置按钮,点击左侧的 Rules,右侧 User Rules,这里就有一个输入框,可以在这个输入框里面输入内容,而这个输入框里面的内容就会作为全局规则
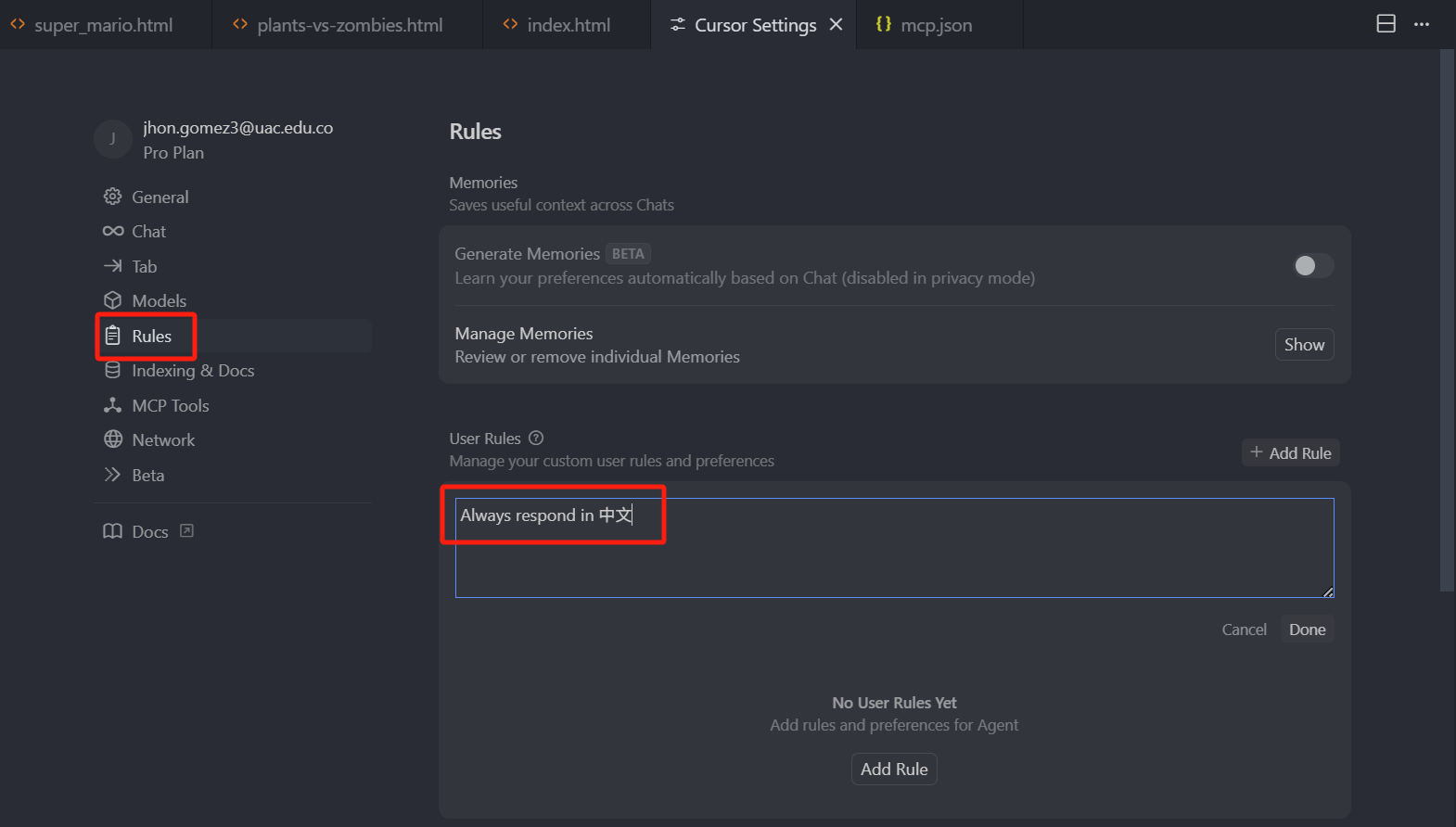
可以看到,我们这里全局规则只设置了一句话:Always respond in 中文(“始终回复中文”),那由于我设置了这个全局规则,所以我在发送给 AI 问题时,AI 给我的回复始终是中文,无论我打开哪个项目,始终会遵循这个规则,因为它是全局的。
再来说项目级规则,在早期版本中,Cursor 针对项目级规则,只支持在项目文件夹根目录,创建一个 .cursorrules 文件,在这个文件内写项目规则,那由于只支持创建一个 cursorrules 文件,所以我们不得不慎重的挑选一些比较重要的规则约束,写进这个文件中。
而在 0.46 版本之后,Cursor 项目级规则,可以支持多个规则文件,不再是只支持 .cursorrules 一个文件。
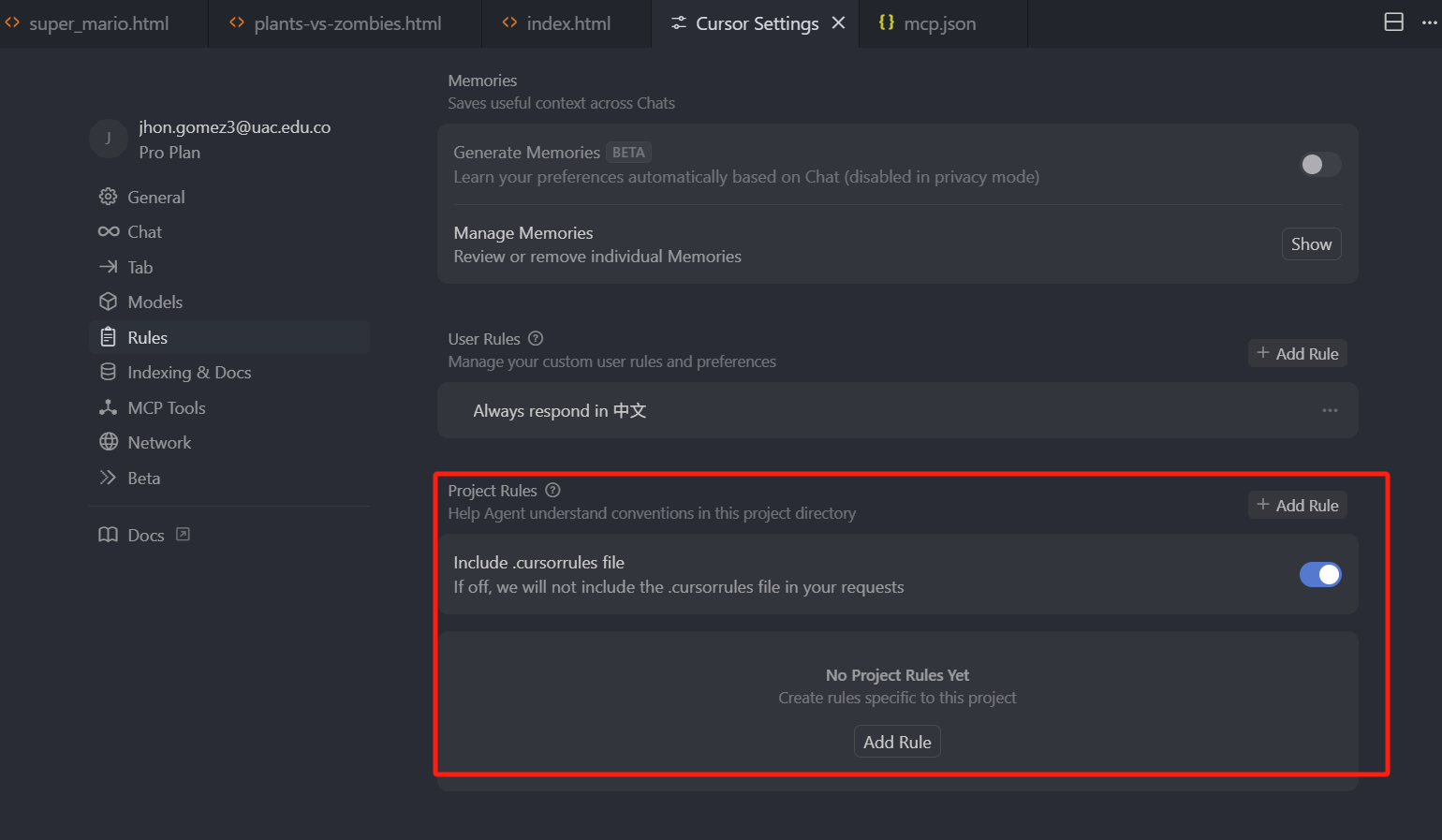
我们可以看到,设置的 Rules 面板中有一个 Project Rules,我们设置的项目及规则,将会在 Project Rules 下方展示,我们现在还没有规则,我们点击右方的 Add new rule,可以随便输一个规则名,回车。
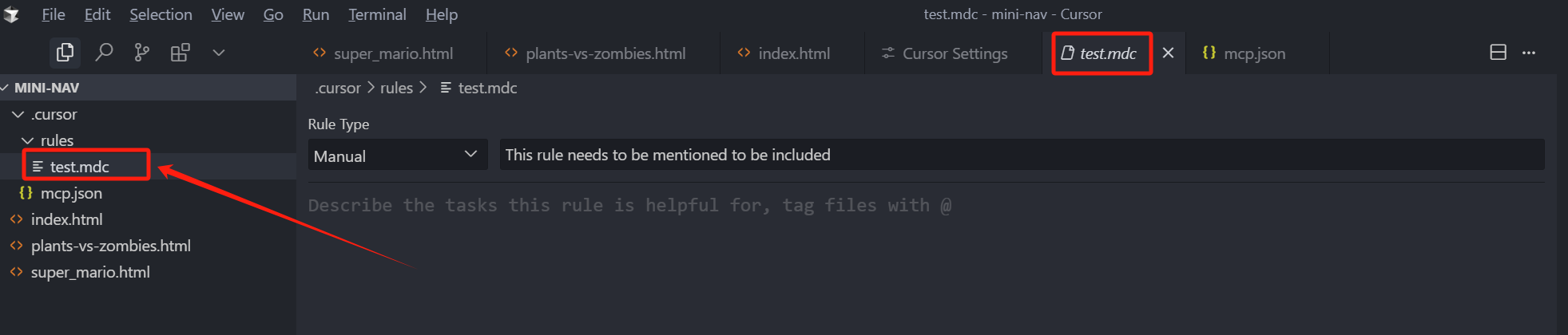
可以看到,Cursor 在项目根目录生成了一个 .cursor 文件夹,当然这个 .cursor 文件夹是我们之前创建的,如果之前没创建,它会自动帮我们创建,然后在这个 .cursor 文件夹下面,创建了一个 rules 文件夹,在 rules 文件夹下,创建了这样一个 test.mdc 的文件,
那 rules 文件夹下面可以放多个 mdc 文件,Cursor 约束这些规则文件以 .mdc 为后缀,并且设置了一些可视化操作的头信息,
mdc 这种格式是使用了 Markdown 格式,大家不了解 Markdown 格式的话,可以直接问一下 AI,学习一下,这种格式文档的语法非常简单,编程领域是离不开 Markdown 的。
我们接着看这个规则文件怎么写,首先我们看头部可以设置的这些信息,我们需要为规则文件选择一个类型
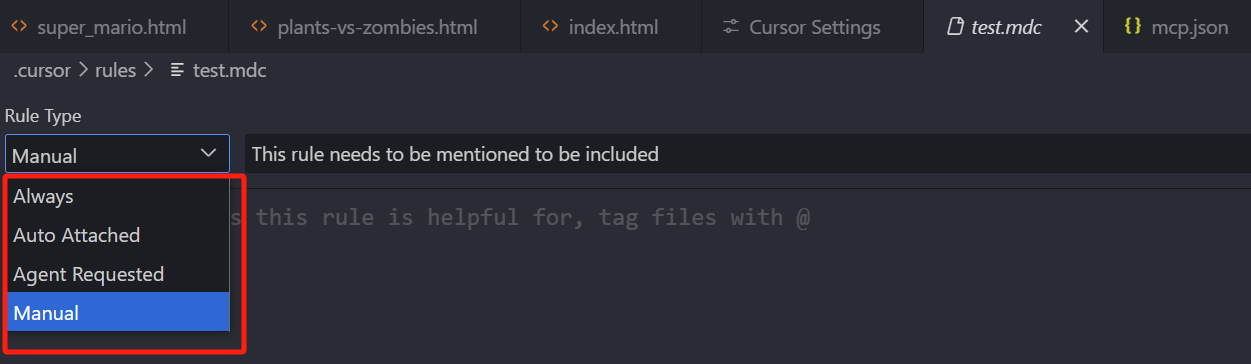
那类型一共有 4 种:
第一个是 Always:

这种类型的规则文件我们保存之后,只要你在这个项目下,给模型发送一个问题,模型就会始终遵循这个规则,它相当于一种项目级的全局规则。
第二种是 Auto Attached:
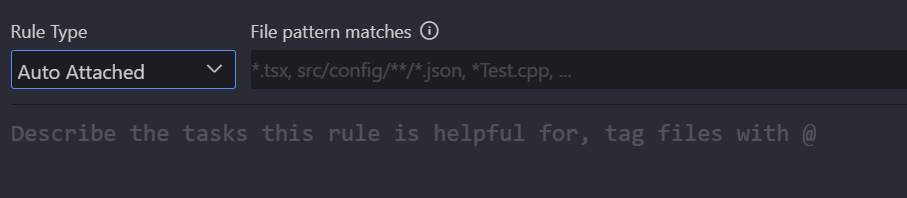
这种类型我们选中之后,可以在右侧填写一个简单的正则匹配,它的作用是设置需要匹配哪些文件,那设置之后,只有当问答中包含这些文件的引用,才会使用这个规则。
第三种是 Agent Requested:

这种类型选中后,右侧会有一个填写 description 的输入框,也就是描述,它是一个必填项,因为在这种模式下,规则的使用权交给了 AI,AI 会通过你填写的规则描述,和我们的问题去匹配,如果它觉得我们的问题需要用到这个规则,那就会自动使用这个规则,而这个自动匹配,是根据规则的描述项去匹配的,所以描述一定要填写的精准,实在不知道怎么写,就让 AI 帮你总结一下:用一句话概括这个规则的主要内容。
第四个是 Manual:
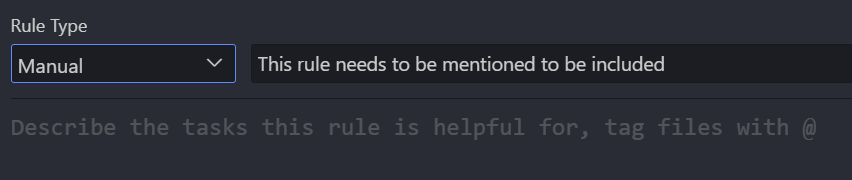
它也是默认使用类型,这种类型只有当我们在输入框中,通过 @Cursor Rules 指令,手动选中这个规则才会使用。
这 4 种规则类型,无论是哪种,当规则被使用时,其实就是将规则文件中的内容附加到了聊天上下文内,为了帮助大家更好的去理解,我们可以测试一下。
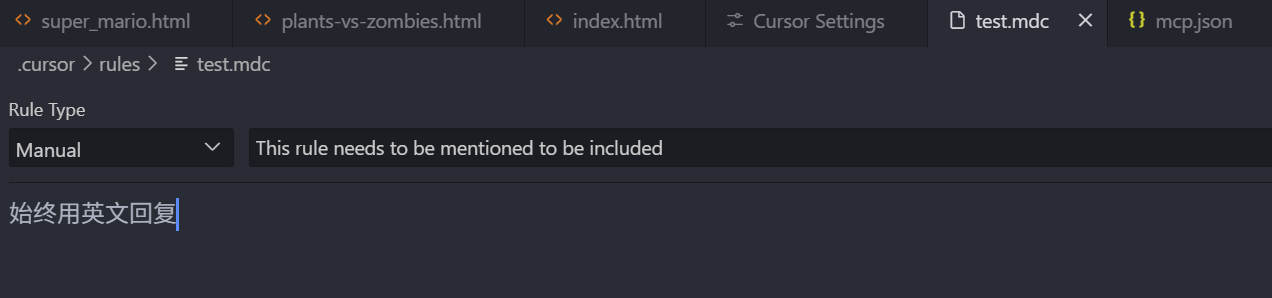
我们先选中 Manual 类型,然后在下方写上一句 “始终用英文回复”,保存,再回到设置面板中看一下,可以看到,设置中的项目规则,已经显示了这个规则
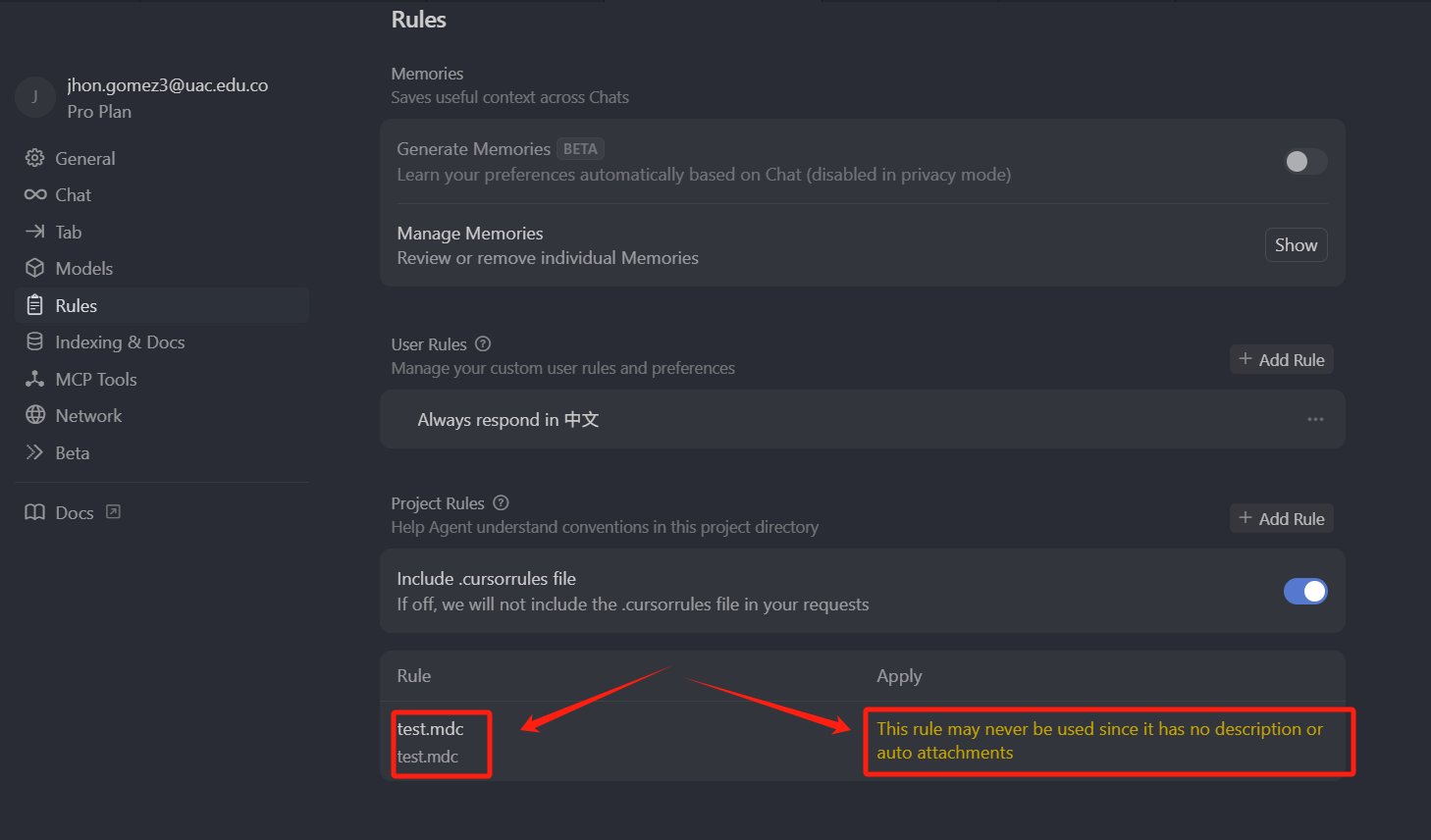
但是它的下面有一句提示,它的大概意思是,由于没有描述或者是自动匹配选项,所以永远不会使用这个规则,这是因为我们选中的是 Manual 类型,这种类型的规则,在任何情况下都不会主动使用,但是我们可以手动使用,我们可以在输入框中,通过 Cursor Rules 指令去使用。
5.2 使用规则
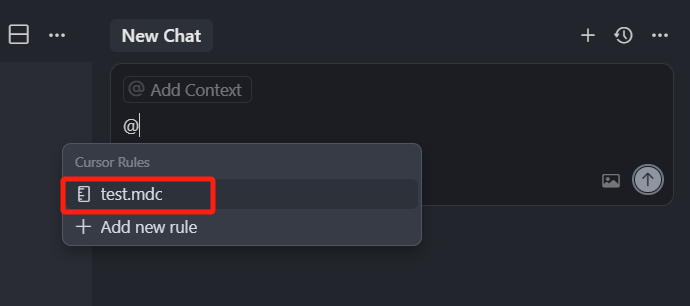
选中这个规则,然后输入 “你是谁”,回车
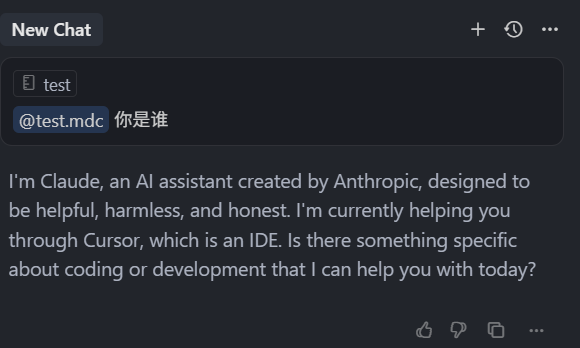
可以看到它使用的是英文回复,说明它应用了这个规则,这里要提一点的是,我们之前全局规则中写了,始终以中文回复,那这里项目规则又写了,始终以英文回复,这种情况下,看来是项目中的 Manual 类型规则被使用了,所以可以说 Manual 类型的规则,优先级是高于全局规则的,我们接着回到这个测试的规则文件,把类型改为 Always,然后再保存。
我们再去看一下,设置面板中的 Rules 规则,
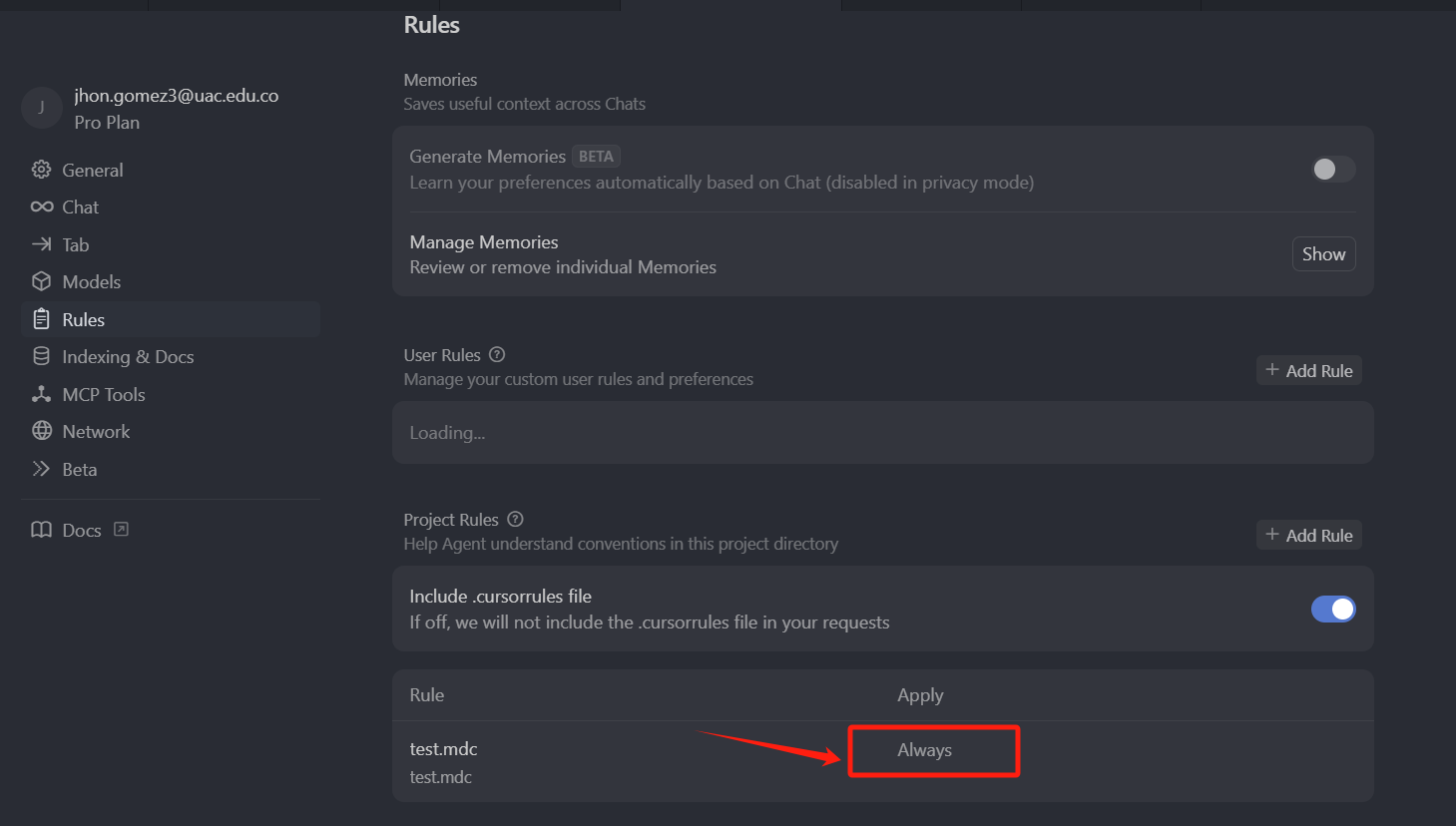
可以看到,由于我们使用的是 Always 类型,那这种项目规则类型,只要是你还在这个项目下发送问题,就一定会使用这种 Always 类型规则,我们之前也说了,它是一个项目级的全局规则,然后我们再打开一个新的上下文,我们直接输入 “你是谁”,回车。
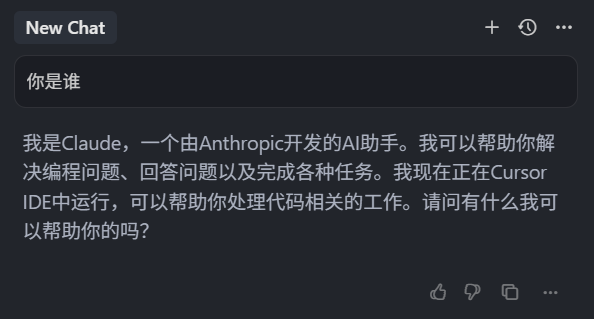
可以看到它的回复是中文,要知道我们这个规则里面,设置的是使用英文回复,而它现在的回复是应用了全局规则,所以我们可以得出一个结论,项目中的 Always 类型,规则优先级是小于全局规则的。
我们再回到规则文件中,把类型改为 Auto Attached,然后我们在右侧的正则匹配中,输入 *.js 保存,
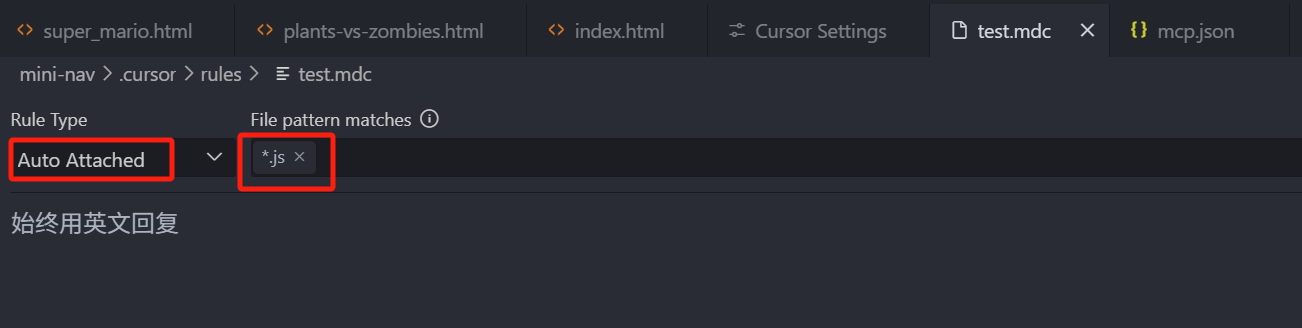
再回到 Project Rules 面板中,那这种类型的规则,它会匹配我们的问答中,是否包含 js 后缀的文件。
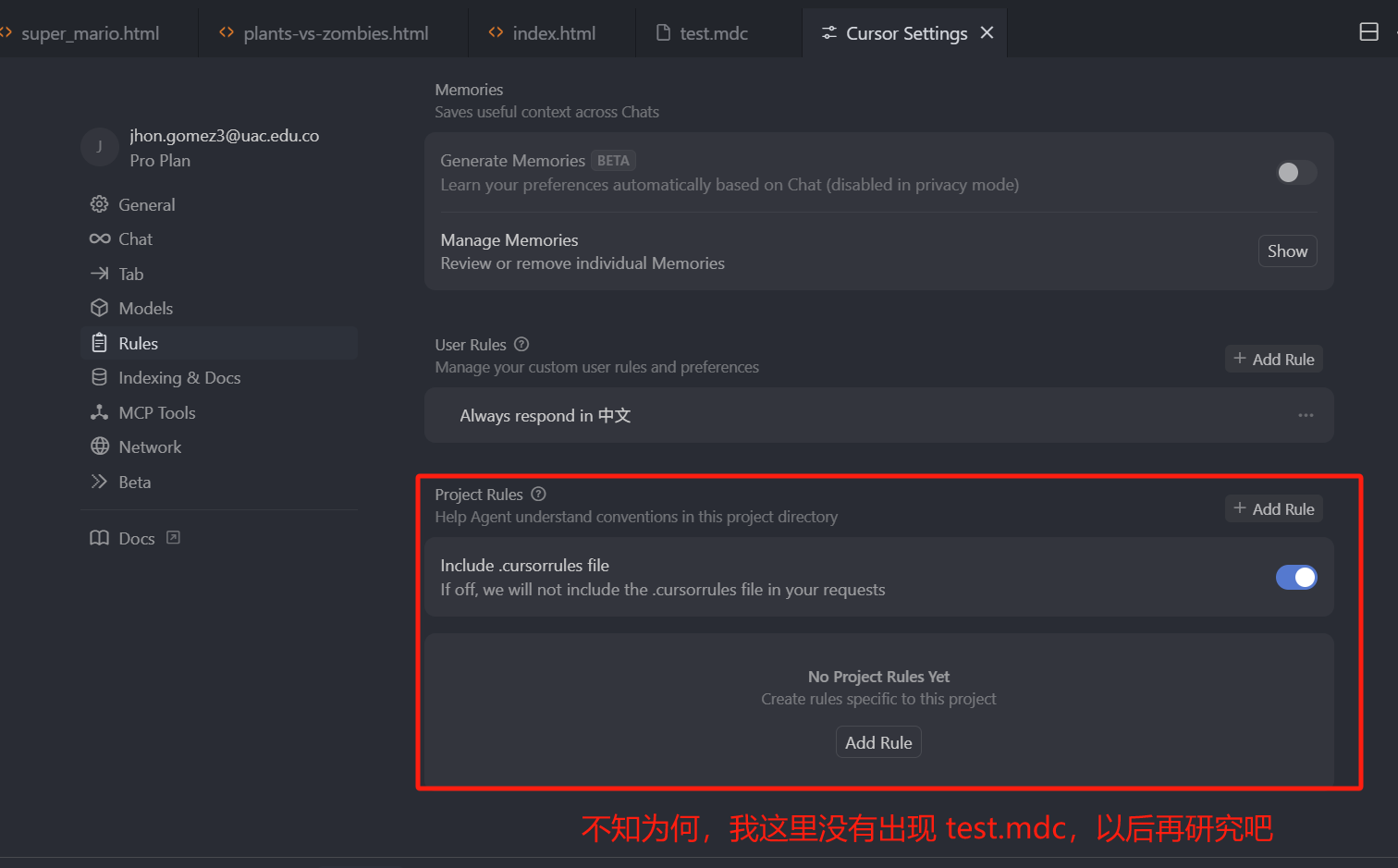
上图中 Project Rules下,不知为何,没有出现 test.mdc,按理说应该是下面截图(视频教程的截图)中的那样:
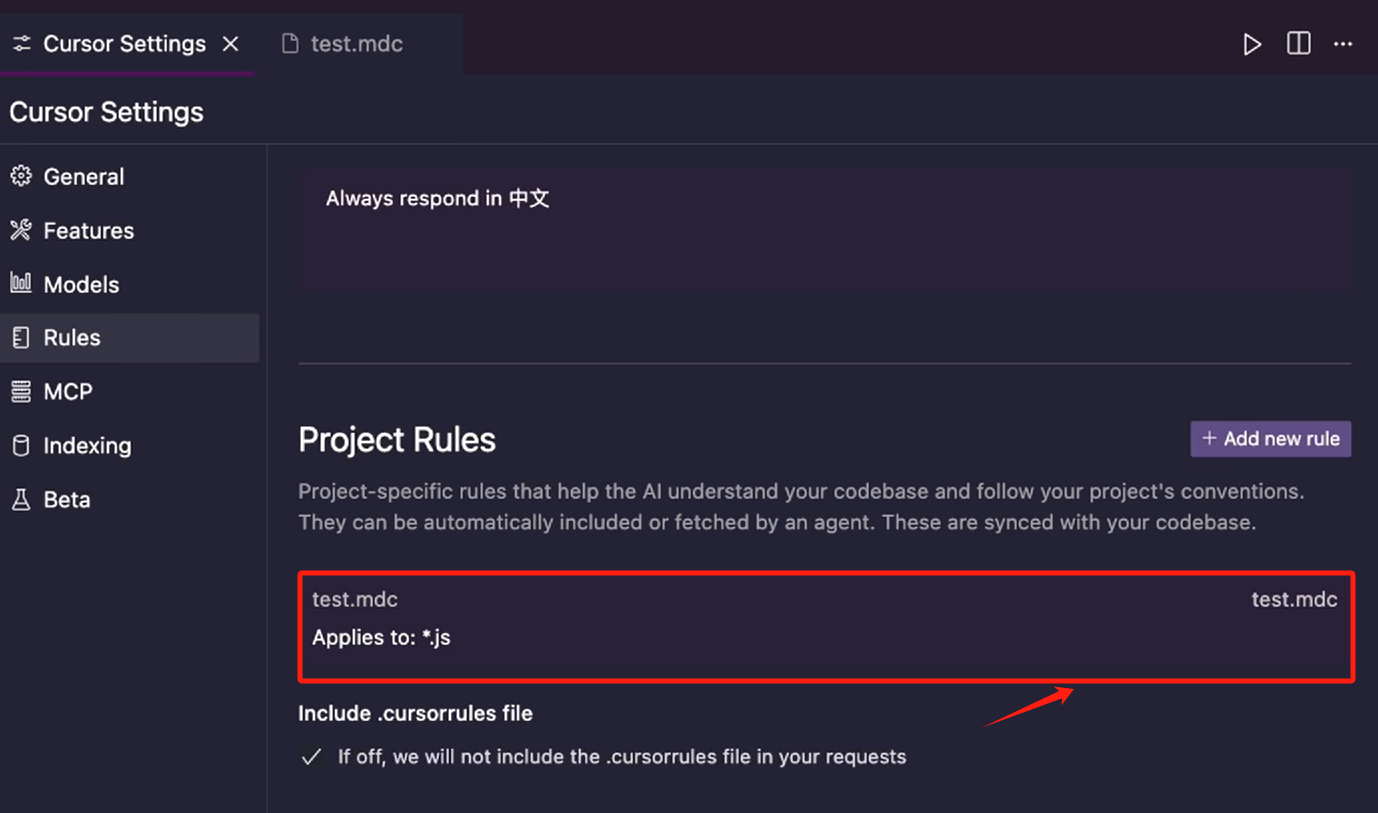
(自从这里之后,我创建的任何项目规则文件都没有在 Project Rules 下 出现过,次奥,为啥)
先不管了,我们打开一个新的上下文,我们直接选中一个 js 文件,然后输入 “这是什么”,回车。

可以看到它的回复还是中文的,也就是说,Auto Attached 这种类型的项目级规则,优先级也是小于全局规则的。
我们再次回到这个测试规则文件,把类型改为 Agent Requested,那这种模式下我们需要填写一个描述,我们在描述中填写,“所有的问答都应该使用此规则”,保存。

那由于我们描述中写了,始终使用英文回复,所以我们在项目下发送问题,一定会匹配到这个规则。
我们新建一个 Chat,输入 “你是谁” 回车,
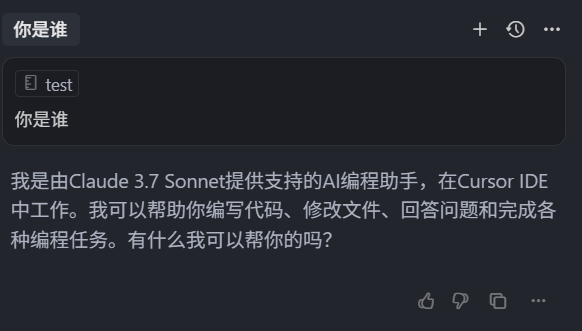
可以看到回复的内容还是中文,并没有按照项目级规则使用英文回复,所以 Agent Requested 类型的项目级规则,优先级也是小于全局规则的,那我们就得出了一个结论:
这 4 种类型的项目级规则,只有 Manual 类型通过手动选中规则文件(使用 @Cursor Rules手动添加规则),它的优先级才会高于全局规则,而 Always、Auto Attached、Agent Requested 这三种类型规则,优先级都是小于全局规则的,当然,除非我们也去手动的选中这个规则(使用 @Cursor Rules手动添加规则)。
为什么给大家演示这个,那由于项目级规则,几种类型的优先级是不一样的,有大于全局规则的,有小于全局规则的,这种情况下,其实我们应该尽量减少全局规则的使用,避免出现一些不可控,或者说出乎预料的情况,那一般我个人只会在全局规则中,设置一个中文回复的规则,其他规则则根据项目去配置。
那除了直接在设置中点击 Add new rule,创建一个规则,我们也可以直接在 rules 文件夹下,创建一个.mdc 后缀的规则文件,
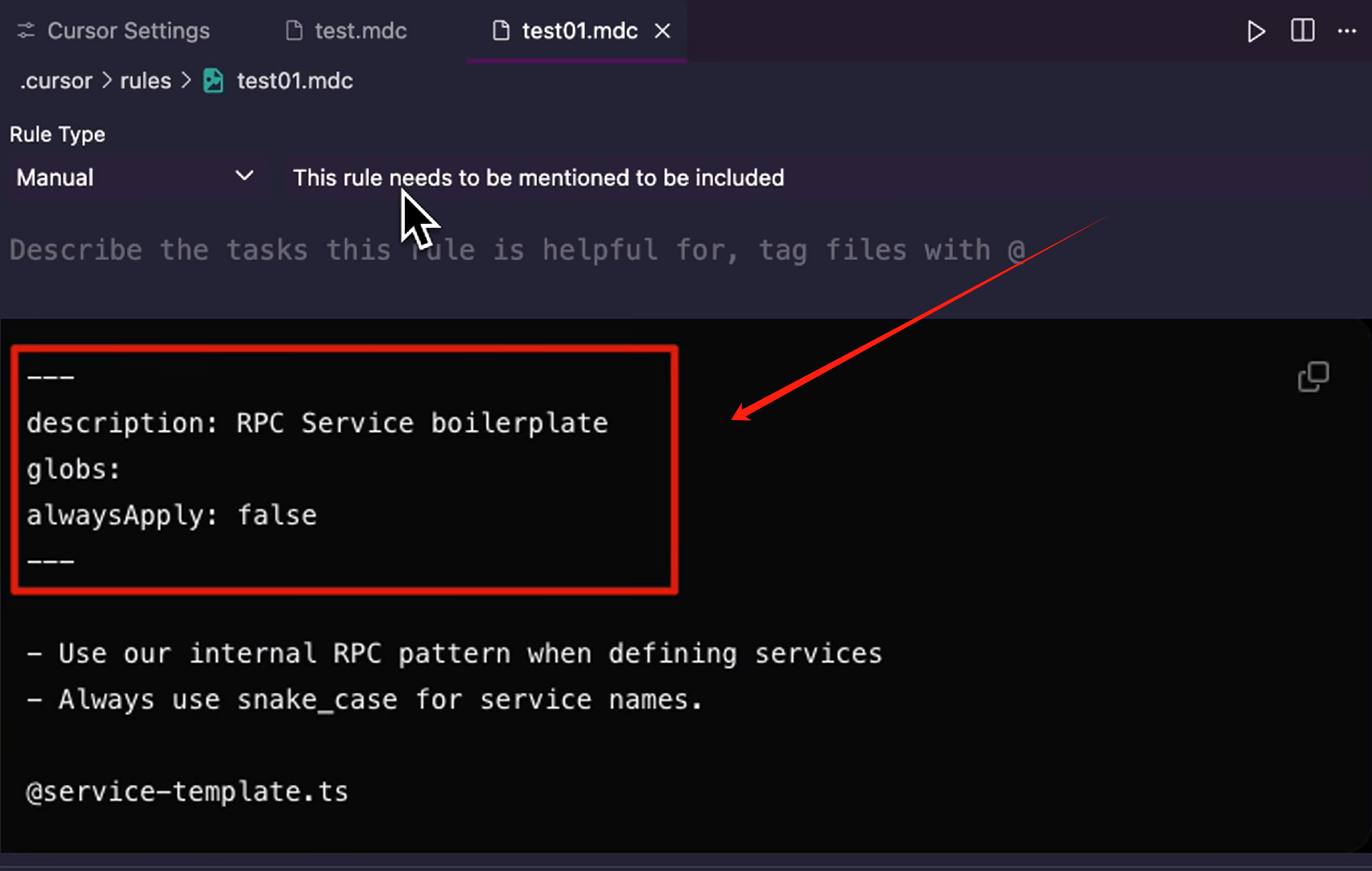
这同样也可以创建一个规则,早期的 Cursor 版本,让模型直接帮我们创建一个规则文件,是不行的,这是因为 Cursor 在 mdc 文件头部,使用了固定的前言格式来说明文件,并且专门为他们做了一个可视化的 UI 选项,其实这些选项背后就是这样一段代码,通过 3 个字段去控制:
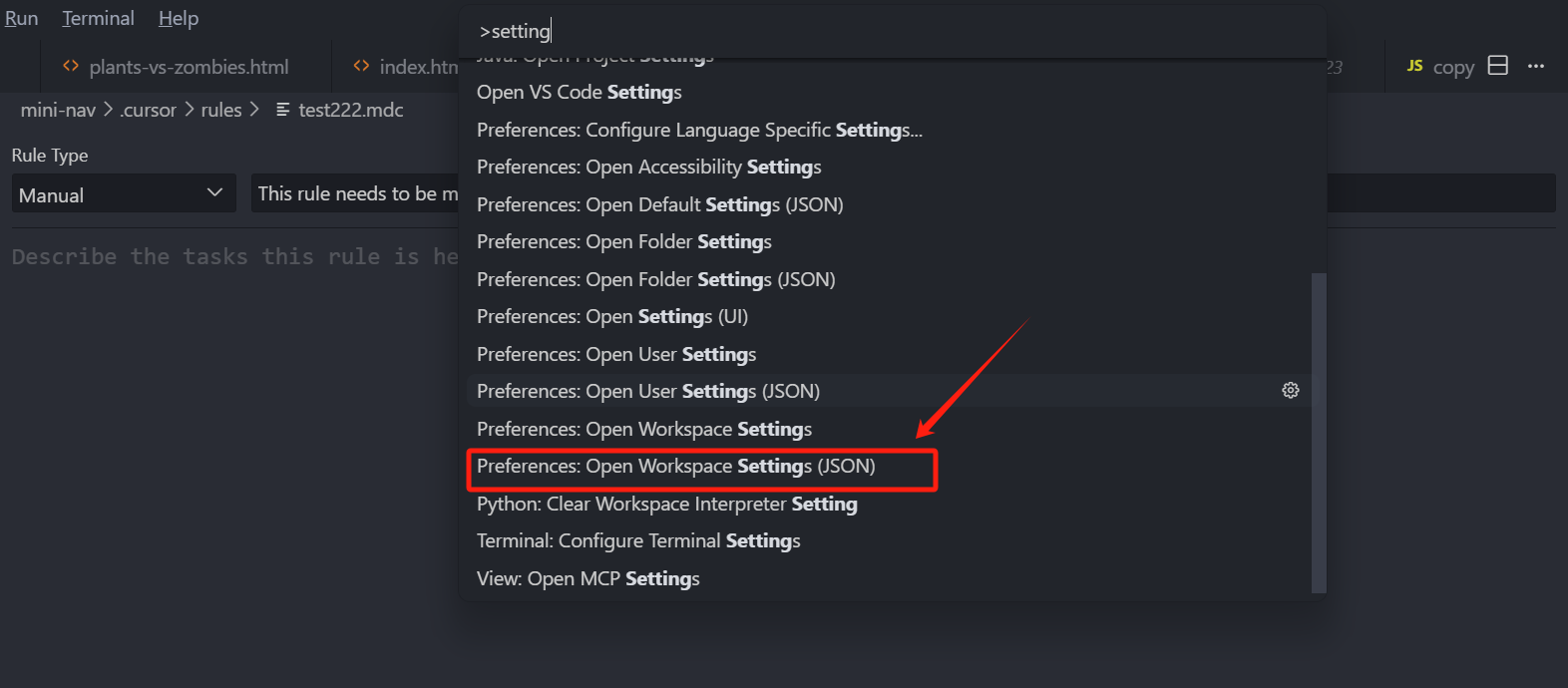
当然如果我们不想使用 UI 面板,也可以直接展示源代码,我们可以按 CMD+Shift+P(Win:Ctrl+Shift+P),输入 settings,在列表中选择 Open User Settings 后面带 JSON 这个
我们直接拖到这个 JSON 配置底部,给它添加一个配置,保存
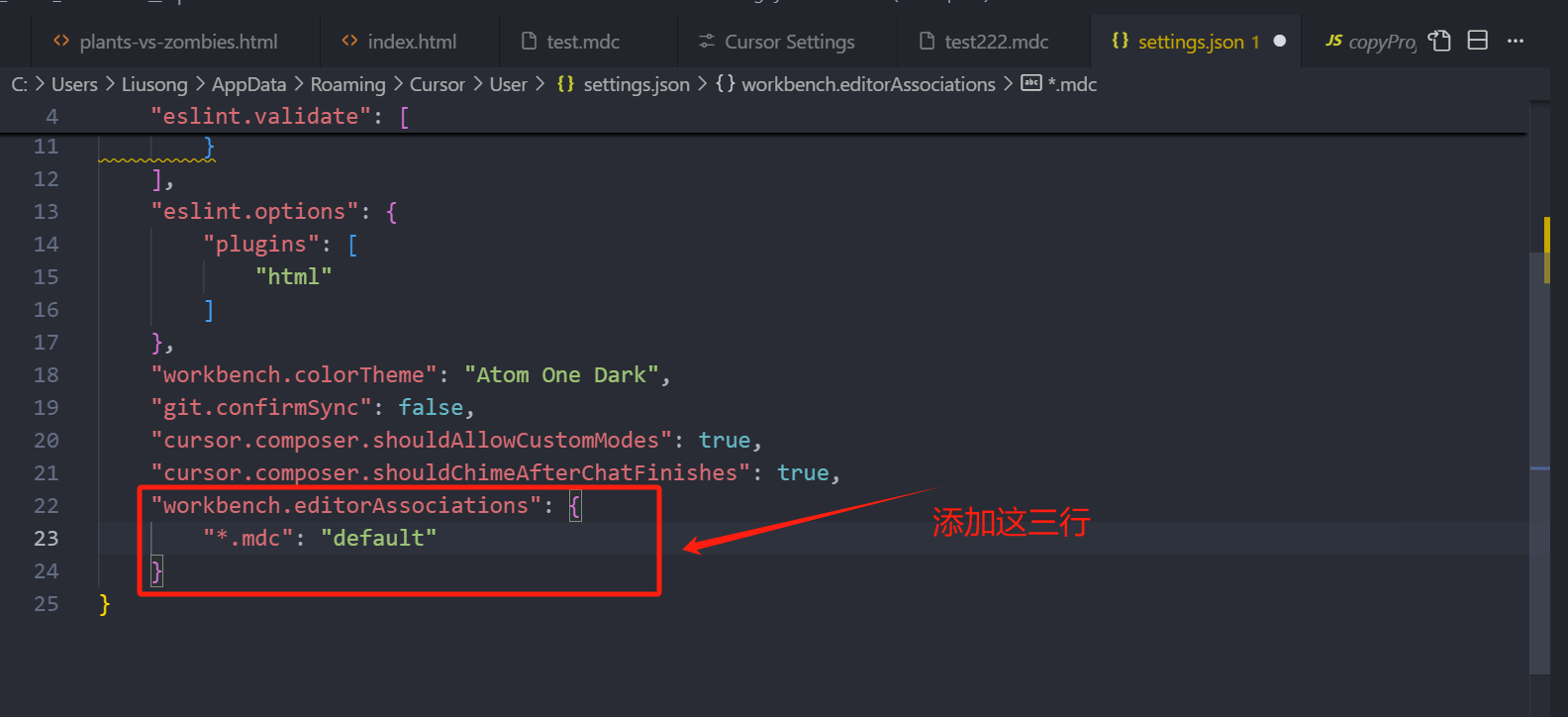
然后把原来的这个规则文件关闭掉,再重新打开
就可以看到,它的上面已经没有了 UI 选项,而变成了这个格式的前言字段。有兴趣的话可以尝试一下。
我们先删除掉这个配置,然后再打开,UI 就又回来了,正是因为这些前言字段,Cursor 把它们做成了 UI 选项,所以早期版本大模型,在直接写入 rules 时,一直有各种各样的 BUG,直到现在依然有很大的问题,当然随着 Cursor 版本的迭代,也可以看出,官方也在尽力的去解决这个自动生成规则的 BUG。
5.3 Generate Cursor Rules
在新版本中,Cursor 也支持了自动生成规则的功能,也就是我们上面说过的 Generate Cursor Rules
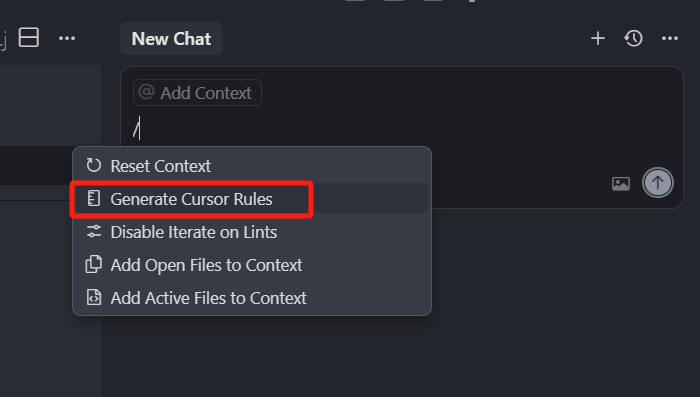
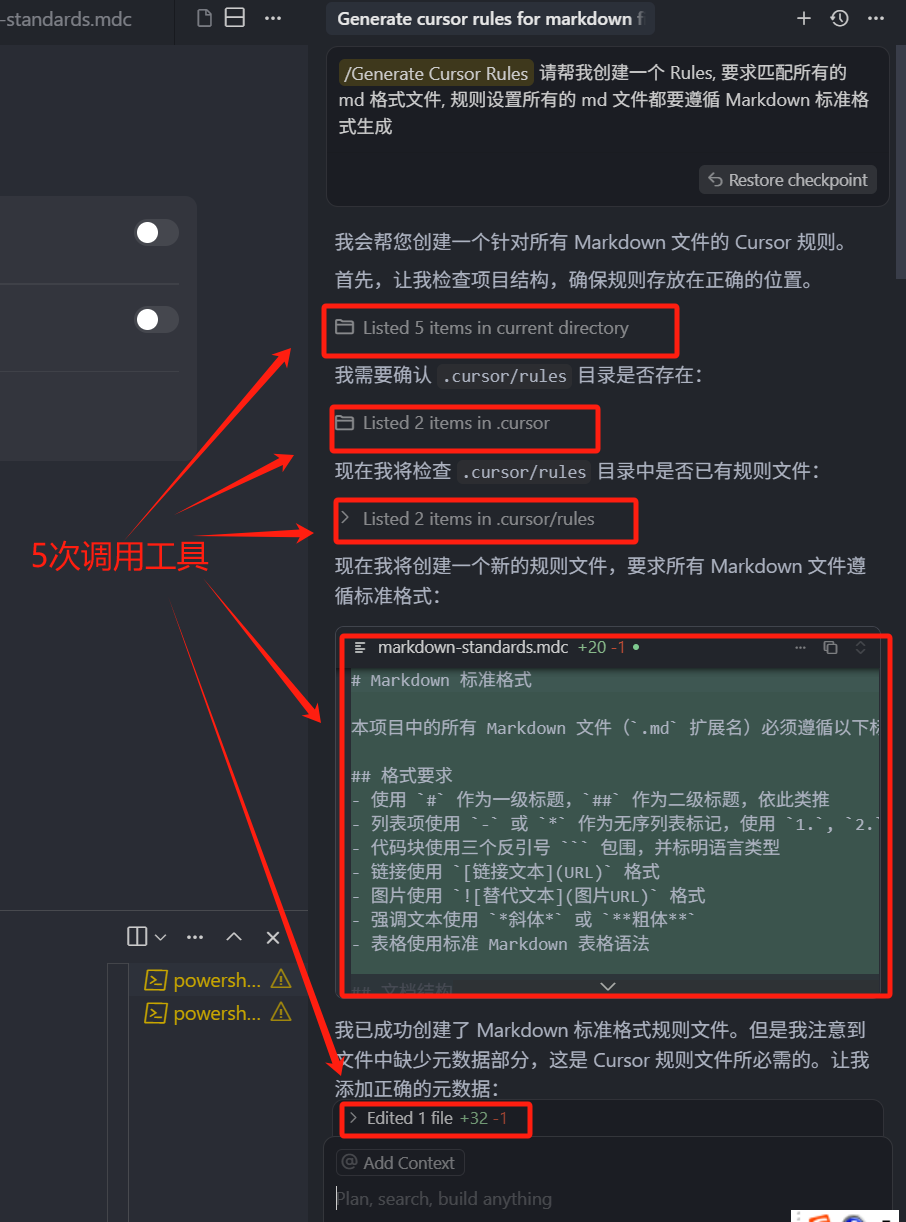
在 Chat 聊天框,可以通过斜杠指令换出一个快捷菜单,然后选中 Generate Cursor Rules,说出我们的需求,即可以生成一个 Rules 文件,我们可以做个简单的演示,打开一个新的 Chat,输入斜杠(/),选中 Generate Cursor Rules,然后输入“请帮我创建一个 Rules,要求匹配所有的 md 格式文件,规则设置所有的 md 文件都要遵循 Markdown 标准格式生成”,回车
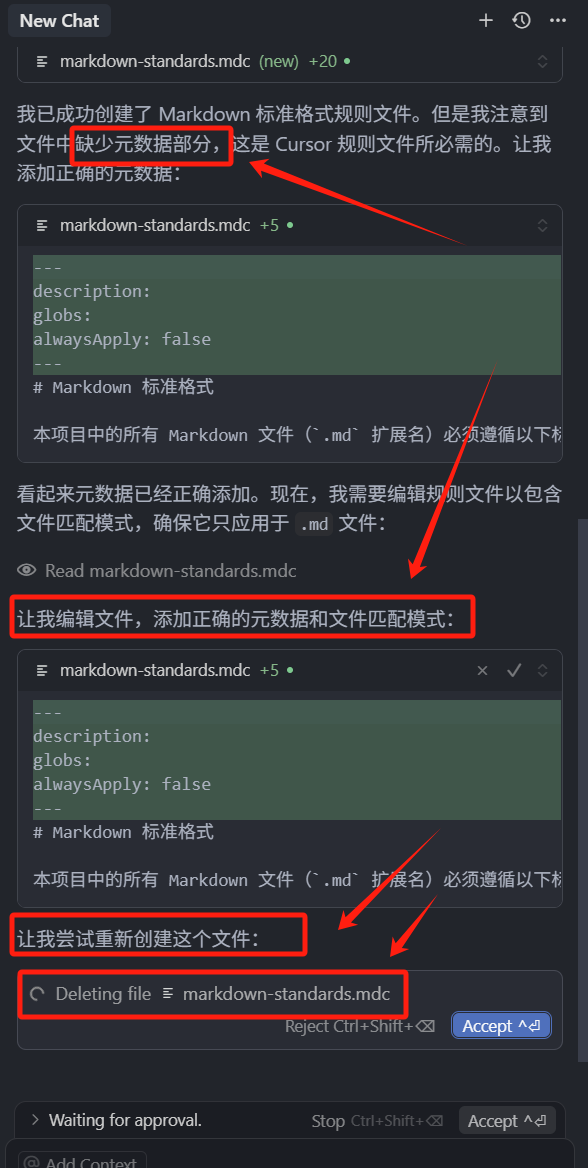
我们可以看到,在它的回答中,它先是帮我们创建了这个文件,然后又检测到,没有添加元数据部分,然后就再帮我们添加头部的元数据,最后还是发现有问题,然后就要帮我删除,可以看出它依然还是存在问题的,但是,这个文件其实已经帮我们创建好了
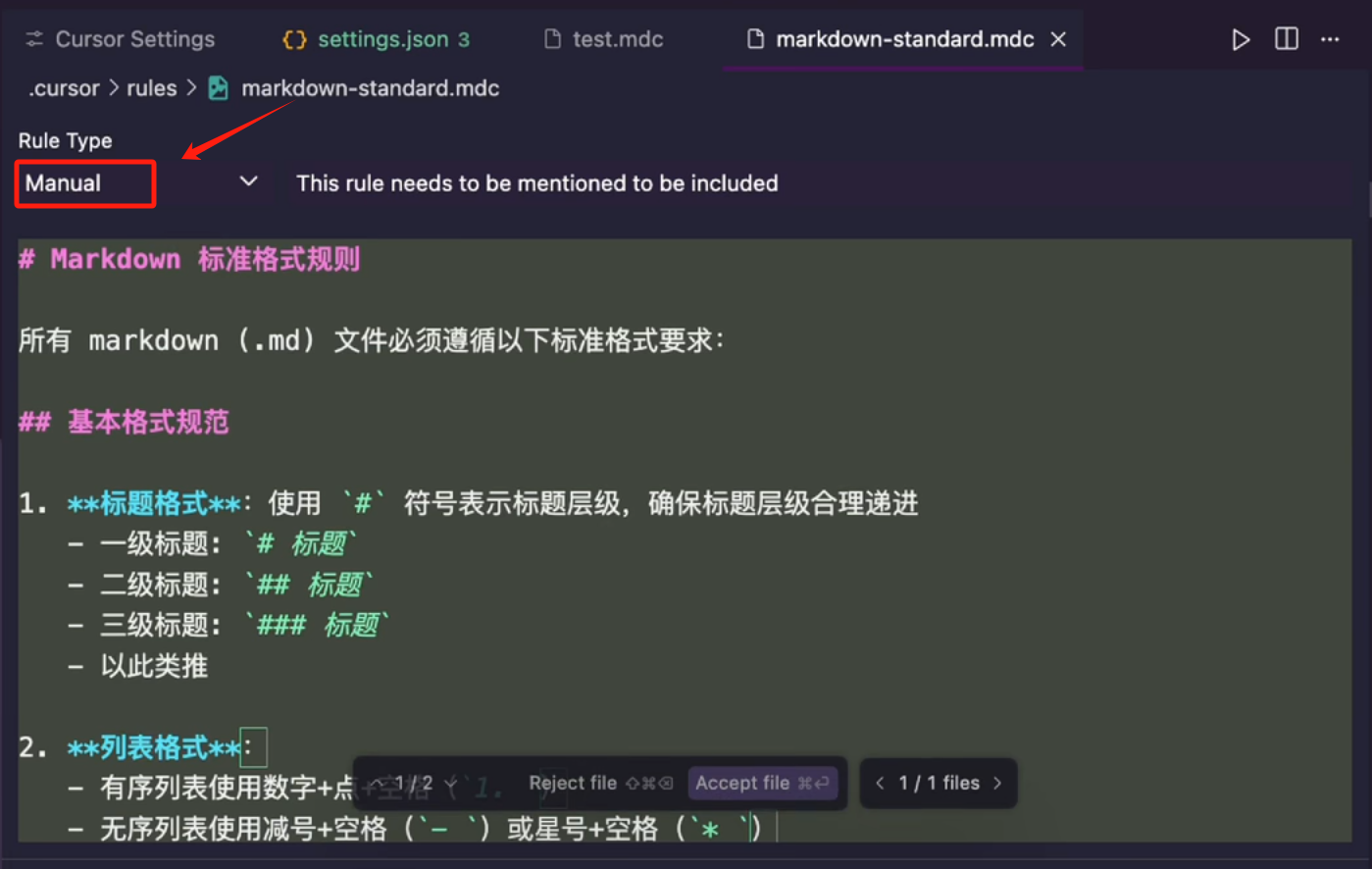
只不过它没有给我们选择类型,这个类型还是默认的 Manual 类型,这里我们直接 Reject 然后 Stop 让它停止,所以说 Cursor 自动生成规则文件,还是有很大的问题,我们看一下它帮我们写的规则,其实就生成的内容来说,不好,但是也不坏,但是就是这个 BUG 就很难受:它生成的规则中,不能帮我们自动填充头部的一些信息。
甚至有一些用户使用这个功能,生成的内容写不进文件,还有一些用户会反复的创建、删除 mdc 文件,就像我刚刚那样,它其实是让我删除掉这个文件,总之还有很大的优化空间,这点我们知道就行,大不了就像我一样,它生成之后直接停止运行,然后我们自己再手动调整一下。
六 Workspace
接下来我们来介绍工作区 Workspace,这其实并不是 Cursor 的功能,而是 VS Code 这款开源编辑器,本身就支持的功能,但是 Cursor 在最新的 0.50 版本中,支持了多根工作区的功能,那我们就要好好说一下工作区了。
假如我们开发一款产品,这个产品涉及一个前端项目,和一个后端项目,那为了能够复用一些需求,同时开发前后端项目,我们之前的做法是,要把两个文件夹放到一块,然后打开他们的父级文件夹,把他们的父级文件夹作为一个项目,导入进 Cursor,那在 0.50 版本之后,Cursor 支持了多根工作区,它可以让多个项目的协同开发变得更简单。
我们直接演示一下,默认情况下,我们打开一个项目时,其实也算是打开了一个工作区,只是这个工作区只有一个项目,所以,这个项目的根目录还是这个项目的,我们可以点击左上角选择 file ,然后点击 Add Folder to Workspace。
选择另外一个项目添加,那添加之后,我们的工作区就有了两个项目
那在这种情况下,Cursor 中的 Codebase indexing,会自动索引两个项目,Agent 模式在自动调用 Codebase 功能时,其实两个项目的索引都是可以用的,
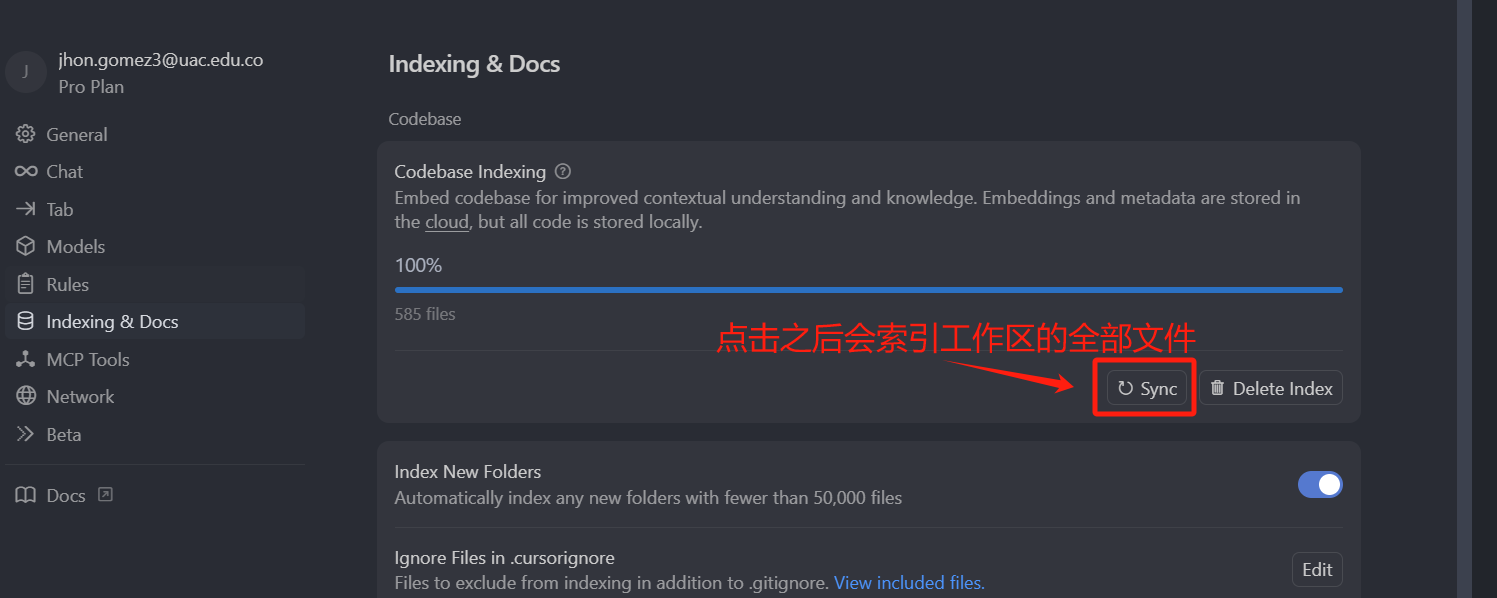
我们点击设置,然后看一下这个 Indexing & Docs,点击 Sync ,可以看到它索引了 585 个文件.
我们来数一数,mini-nav 这个项目下,它其实索引了 5 个文件,因为 .cursor 这个文件夹,它是点(.)开头的,所以它会被忽略掉,然后 hello123 这个项目下会索引 580 个文件,.gitignore 文件也会被忽略掉,.cursor 文件夹也会被忽略掉,那同时在 .gitignore 文件下,我们写了这个 node_modules 文件夹,node_modules 也会被忽略掉,

再来看一下它们的 Rules,其实可以看到这个 Project Rules(用的是视频教程里的截图,如下)
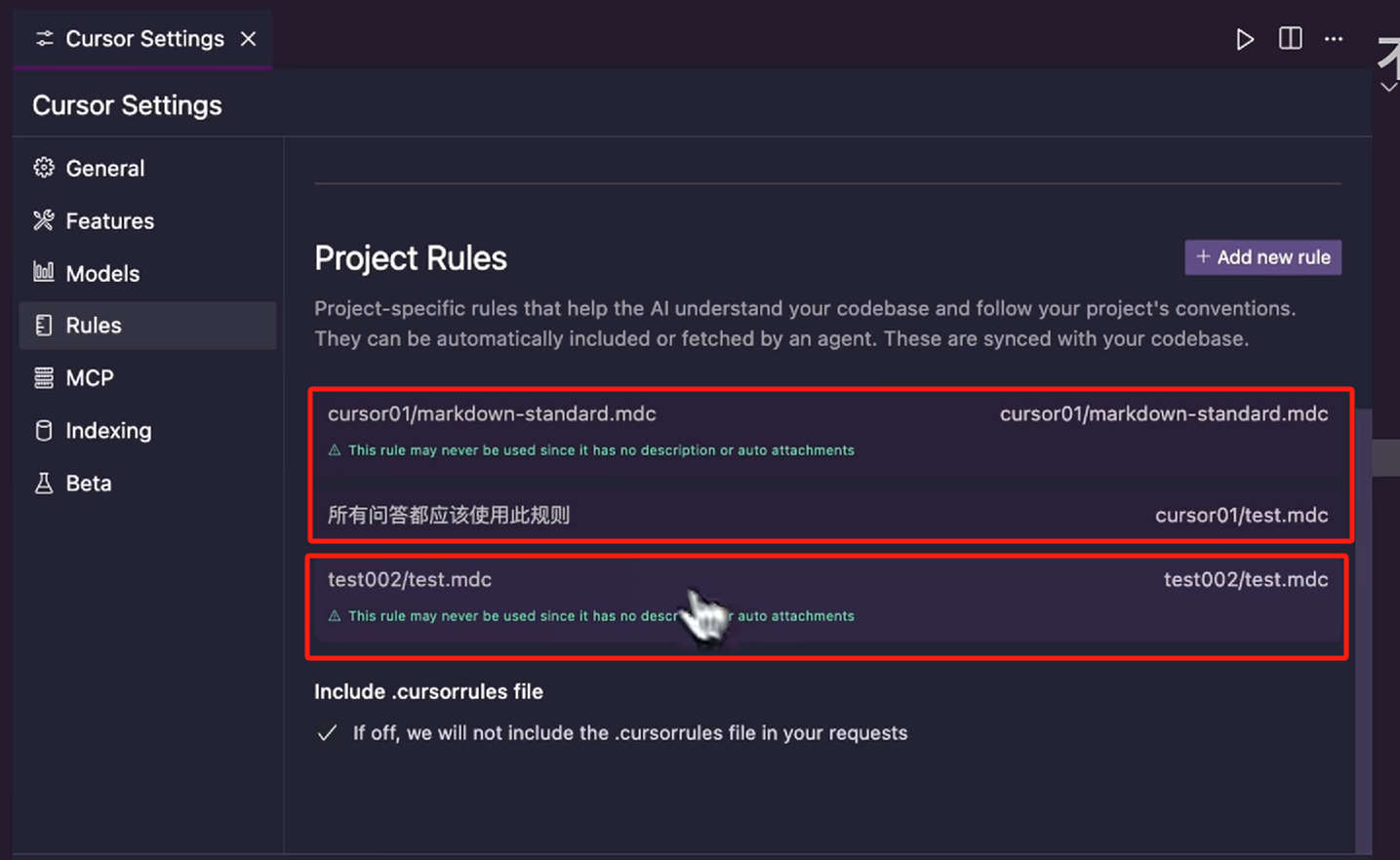
上图的 Project Rules 下面有三个 Rules,前两个是 cursor01 下面的,最后一个是 test02 下面的,那我们在工作区中,如果有多个项目,他们的 rules 规则是通用的,也就说我们可以在这个聊天框里面,使用 @Cursor Rules 可以显示的使用不同项目下的 rules 文件。
其实这种效果,和我们直接打开一个文件夹,文件夹下放多个项目效果是一样的,但是使用工作区,两个项目可以在不同的位置,每个项目中都可以有自己的配置,我们在聊天中,既可以选中一个项目下的文件,也可以选择另外一个项目下的文件。
我们可以使用工作区,同时打开一堆项目,打开之后,我们只需要点击左上角的文件,然后选择将工作区另存为
输入一个名字,然后选择地址保存,我们就可以保存一个工作区的 JSON 文件,
下次打开这个工作区文件,就可以直接打开这个工作区了,这其实是一个很方便的功能,其实到这里核心功能就已经介绍完了,还有一些琐碎的功能需要提一下:首先 Cursor 的 Chat 聊天框中,现在也是支持上传图片了,0.44 版本其实也支持,但是那个时候上传图片,它只支持 OCR 文字识别,没有文字的图片直接 GG,那现在的话,上传图片,会使用多模态的模型解析图片,我们可以尝试一下给它一个图片,然后问这是什么,回车
我们看一下这张图片,
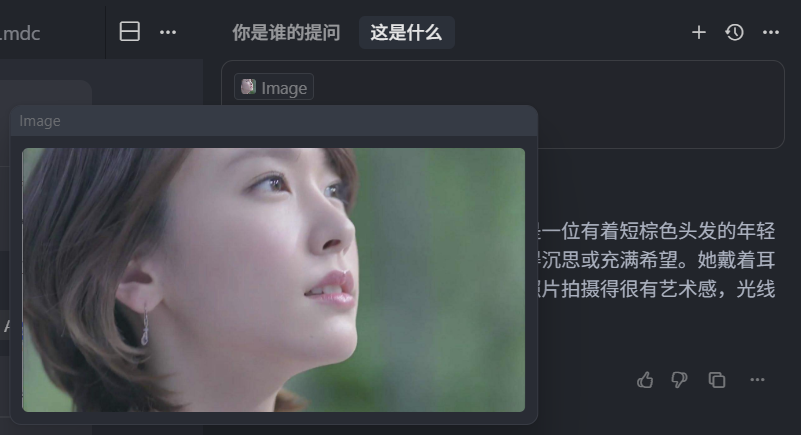
其实可以看到这个没有文字的图片,它也是识别出来了,所以给它一个 UI 截图,让它帮你去实现 UI,目前也是可以用了,另外就是在 0.49 版本中的一次更新中,调用 MCP Server 时,它也支持了直接输出图片,这些都比较简单,所以就不浪费时间演示了,大家自行体验。
上期视频在讲 Codebase 功能时提到了,由于 Cursor 会索引项目文件,上传到远程使用矢量数据库中,那项目代码中,如果有一些隐私文件不想被索引的话,我们是可以在根目录创建一个,.cursorignore 文件来忽略某些文件,这块儿不知道或者不理解,可以看一下上期视频,或者是看一下官方文档,我们要说的是,在新版本中,Cursor 支持并且默认配置了一份,全局的忽略文件:
我们可以按快捷键 CMD+Shift+P(Win:Ctrl+Shift+P),然后输入 settings,从列表中选中 “Open Workspace Settings”,
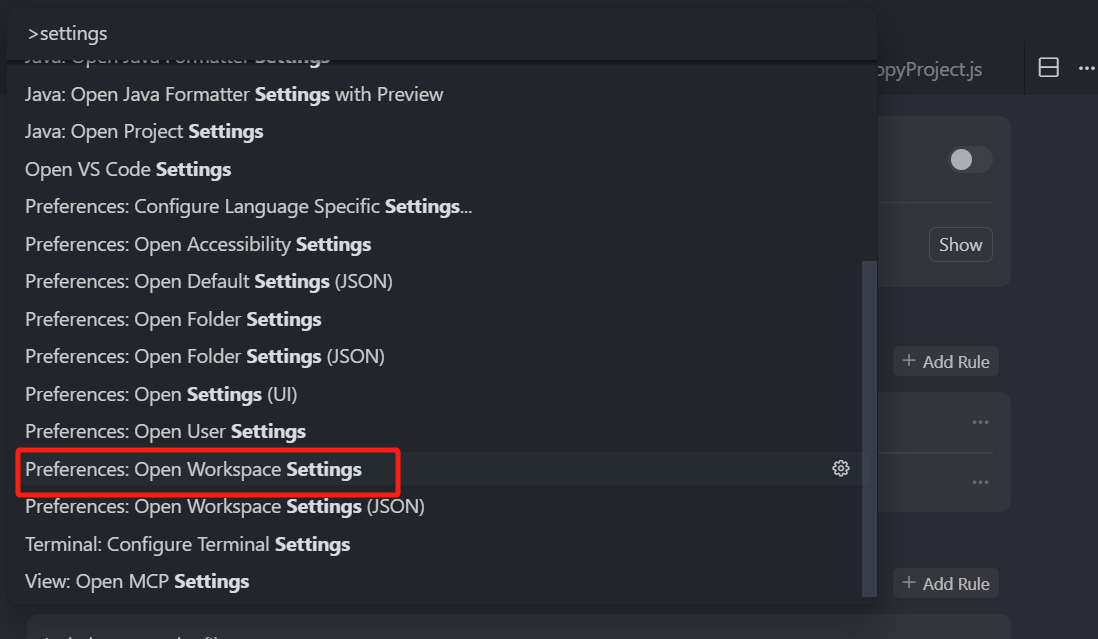
然后在上方的搜索输入框中,输入 “global cursor ignore”,就可以看到,我们这个全局的忽略文件配置
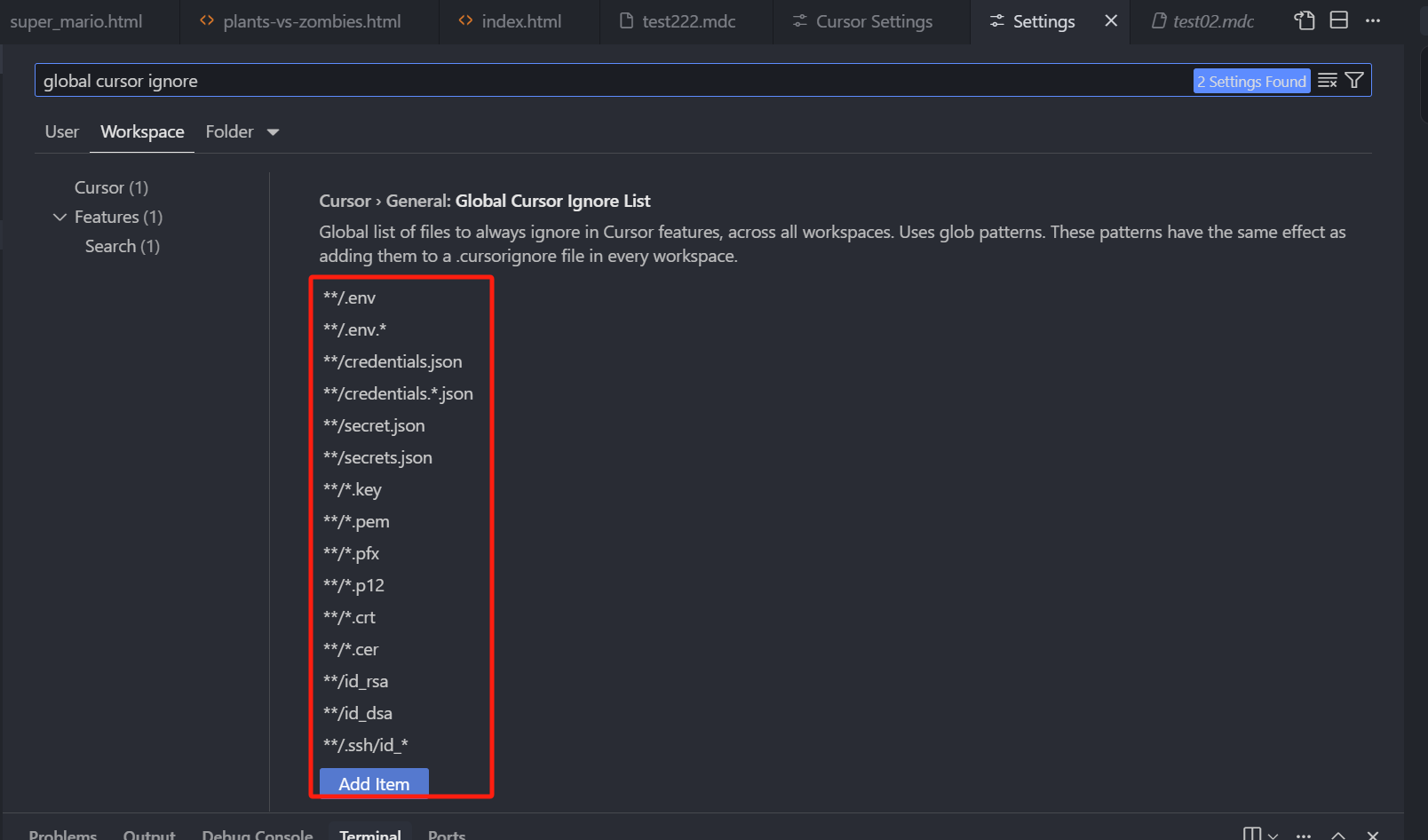
它默认给了我们一套配置,我们也可以自行配置,那非编程赛道的朋友们,听不懂也没有关系,用默认的就好,问题不大。
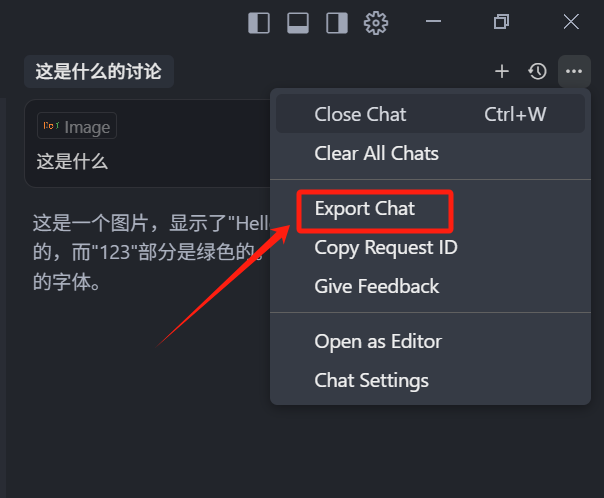
然后就是应社区的广大网友要求,Cursor 在 0.50 版本终于上线了 Chat 导出功能,我们可以选中一个 Chat 上下文,点击右上角的三个点,然后选中 Export Chat,点击导出
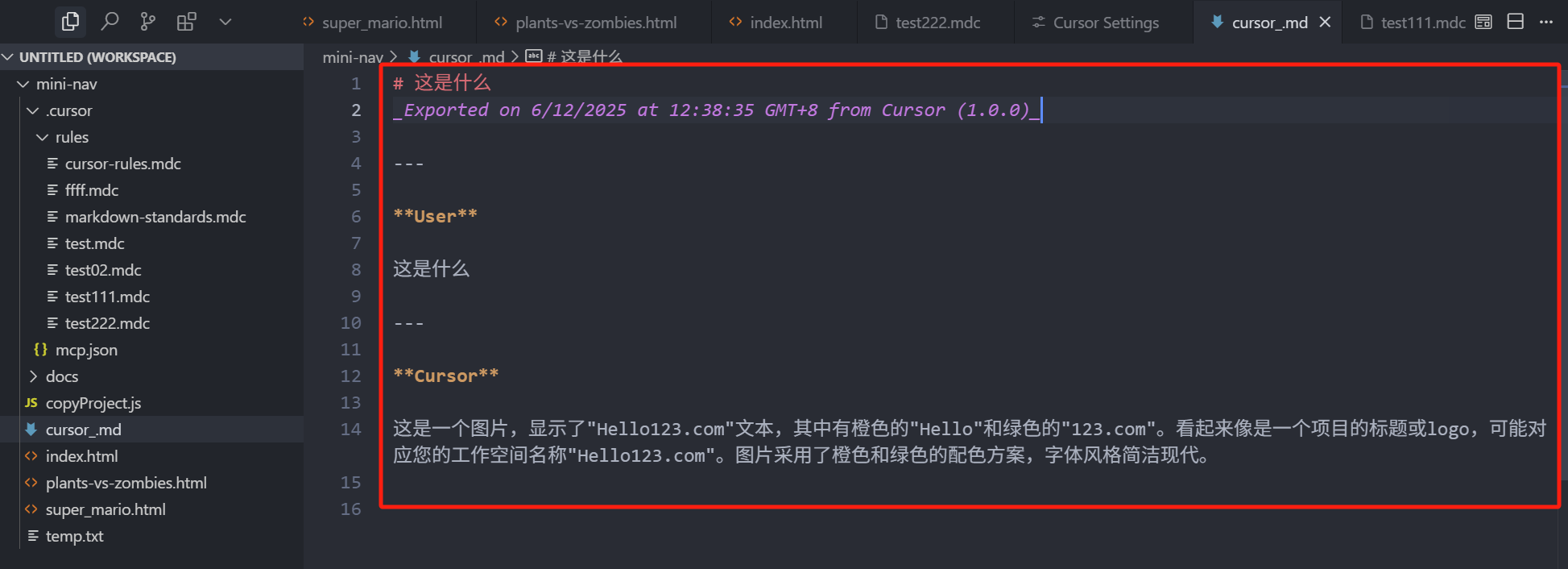
可以看到,这样就将整个 Chat 的上下文记录,完整的导出了一个 md 文件,当我们想要分享给别人自己的某个 Chat 上下文记录时,就可以导出发送给别人这样一个 md 文件,这整个 Chat 的记录都有
那在 0.50 版本中,Cursor 也支持了一个叫 Background Agent 的功能,可以让我们在后台或者是远程环境中,运行一个 Agent 代理任务,那这个功能,相当于让 Cursor 支持了更多的并发任务,只不过它不是在 Cursor 中运行,如果我们要使用它的话,可能需要单独去下载一个 Background Agent 版本的 Cursor,它可以在远程实例中安装运行,也可以在虚拟机中安装运行,当然这只是我的一些猜测,因为这个功能目前还是 Preview 版本,还没有正式的上线,那这种并发的任务它是在后台执行的,并不是在 Cursor 中执行的,比较适合一些批量复杂,但是又不需要我们人为把控的一些任务,等它正式上线了之后,我们再来说这个事情,到时候看看有没有更有趣的玩法。
另外还有一个点就是,如果大家想要第一时间体验 Cursor,新版本的话,可以点击右上角的设置按钮,然后点击 Beta,在右侧我们可以选中 Early Access,
选中它就是早期访问的意思,开了之后,只要有新版本就可以更新体验,我的建议是新老版本它都不是很稳定,那不如用最新的,大不了更新后不喜欢卸载重装旧版本嘛,问题不大,Cursor 由于更新迭代速度都很快,所以它其实一直不那么稳定,我目前的演示版本是 0.50.1(我做笔记时候的版本是1.0)
七 技巧
7.1 单一职责上下文
很多朋友会经常性的问我一个问题,Cursor 是不是又降智了,为什么感觉越用 Cursor 越傻,虽然我不能完全保证,但是其实所谓的降智越用越少,大概率是朋友们姿势不对,有的朋友在使用 Cursor 开发过程中,觉得新开一个 Chat 之后,之前调教给 AI 的那些内容,它就不知道了,所以经常可着一个 Chat 上下文使劲的造,甚至都已经明显感觉到,模型开始恍惚了,还在一个 Chat 里面造,直到 Cursor 给出了警告,如果大家在聊天过程中,看到了输入框下方出现了这样一行字
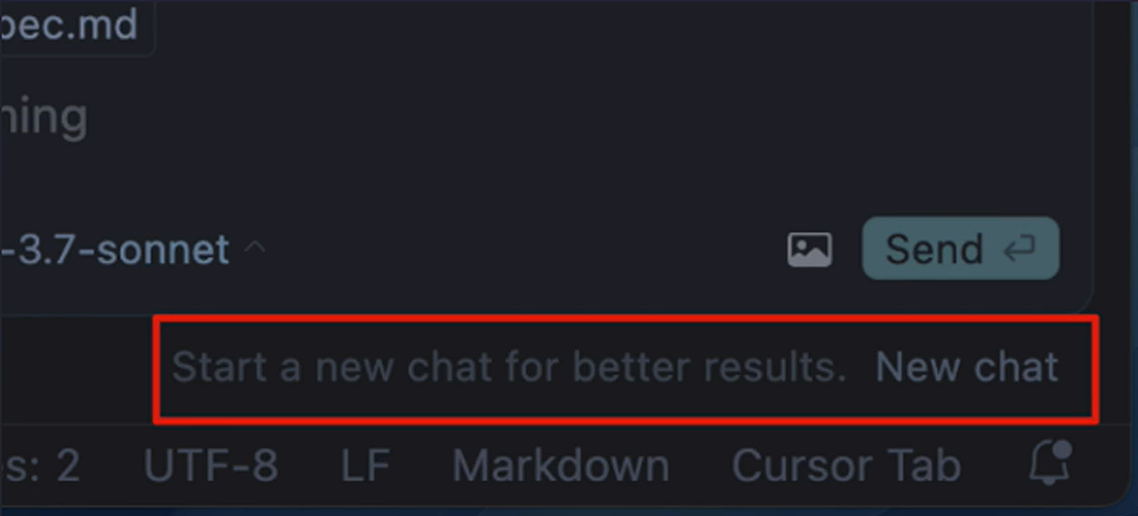
那么恭喜你,你已经造到了大模型的上下文限制,大家千万不要这样做,通常我在开发中,一个 Chat 上文只做一件事,做完就新建一个 Chat 做第二件事。
具体方案方案如下,这里介绍 3 种:
第一,完整的需求,应该落在统一的需求文档中,我们让 Cursor,写代码的时候是根据文档去写的,新开的 Chat,只需要把需求文档引用一下,文档是边界,要做的事情都在文档里面了,不在文档里面的就是超出了边界也无需理会,所以并不会丢失什么东西。
第二,如果我们发现,每个 Chat 中都要强调一些类似的东西,那我们应该意识到,这个强调的点应该作为一个规则,我们应该创建一个 rules,而不是在每个 Chat 中反复的去强调。
第三,如果上面的 1 和 2 都不匹配,确实新任务实在和之前的Chat 有上下级顺序关系时,我们可以使用前面讲过的,@Past Chats 指令,通过 @Past Chats 指令,来选中之前的 Chat 记录,这样,Cursor 就会总结上一个 Chat 的内容,给到新 Chat ,作为新 Chat 的上下文。
这三种方案,基本上覆盖了所有的短上下文的问题情况,所以,没有什么任务,是非得我们一直在同一个 Chat,上下文中去完成的,一定要把新开上下文这个操作,刻在脑子里,这样做的好处很多,首先模型不会因为上下文太长而恍惚,也就减少了所谓的越用越傻的可能性,一个非常长的上下文中,模型为什么会恍惚,因为我们在使用 Cursor 时,并不是每一个问题都是有效回答,我们问了一个问题,Cursor 回答错了,一般情况下我们都会继续换个方式问,直到 Cursor 的输出符合我们的需求,所以在一个上下文中,不可避免的有大量无效冗余的信息,这些信息都是为了服务一个任务还好,如果上下文中执行了,多个不同的任务,每个任务都有很多无效信息,我们还在这个上下文中继续追问,模型会持续参考上下文的内容,自然就会恍惚,所以,短上下文、单一职责上下文,则可以有效的规避这个问题。
如果我们每个 Chat 上下文,都是单一职责的,我们可以理解为,每个 Chat 中只做一件事,注意,是只做一件事,而不是只能发一个问题就要新开 Chat,每个 Chat 的上下文,只围绕一件事去处理,粒度很细,我们要回顾修改某个功能点时,只需要切换到这个历史的 Chat,接着改就可以了,而新版本 Cursor 增加了一个小功能,它给每个上下文的底部,都增加了一个 Review Changes 的功能
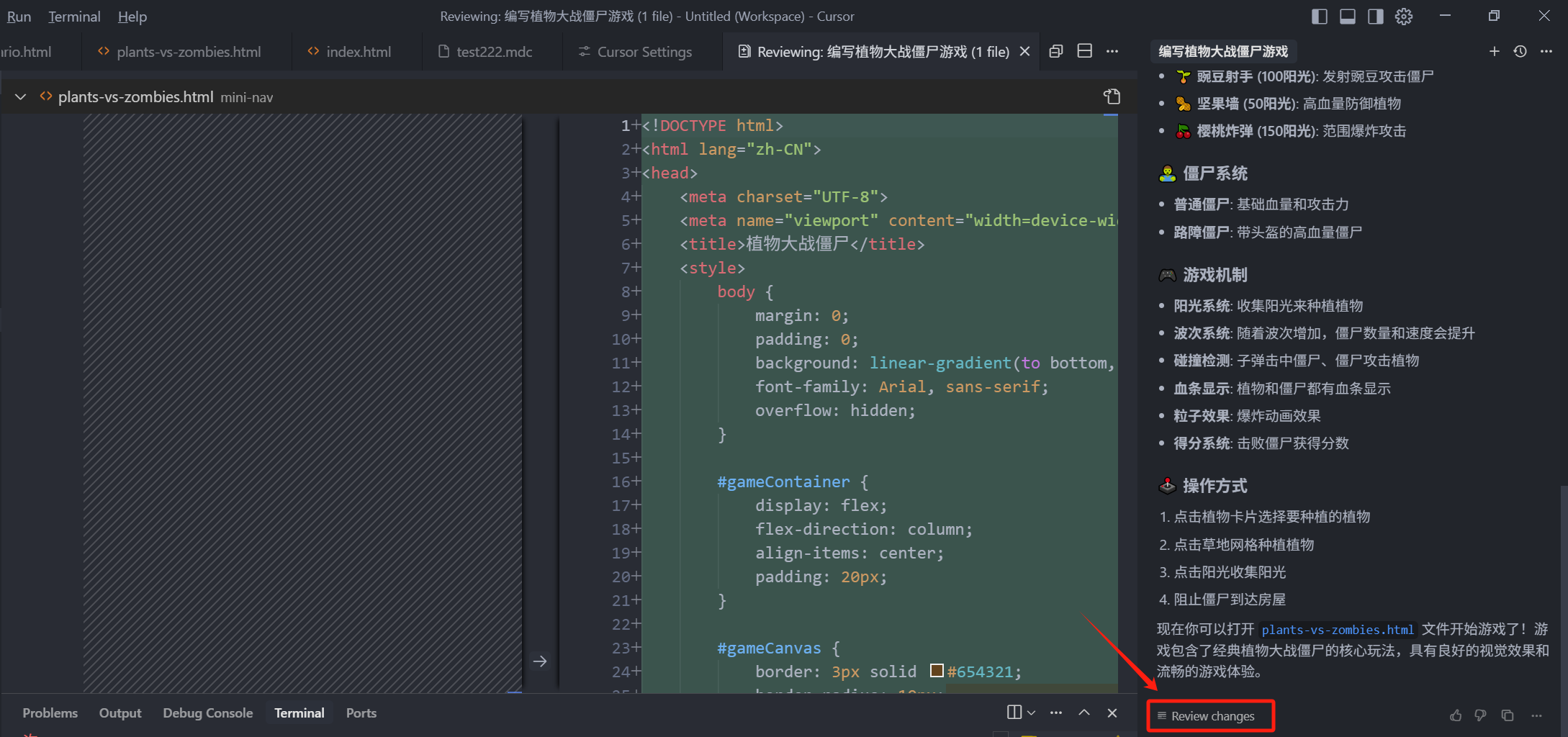
也就是说,我们可以点击 Chat 底部的 Review Changes,来查看这个 Chat 上下文中,都修改了哪些点,试想一下,如果我们在每个 Chat 上下文,都只做一件事,那么我们在回顾时,可以直接点 Review Changes,来查看针对这件事情的所有改动,反之,如果我们在一个 Chat 中又干这又干那,那么,Review Changes 这个功能就是个摆设,因为我们并不能通过 Review Changes 来查看,哪个步骤改了哪些内容,它只是针对一个 Chat 的上下文的整体的改动记录。
而且在使用 @Past Chats 的指令时,如果我们始终遵循单一职责,那么 Past Chats 的指令,为我们总结的 Chat 上下文的内容,就会始终围绕着这个单一职责的任务点,Cursor 生成的总结自然也就会清晰明了,避免了过长或者任务繁杂的上下文,导致总结时遗漏了某些内容,如果我们需要将多个任务总结纳入到新的上下文,使用 @Past Chats 指令,多选中几个历史 Chat 就可以了。
比如我们新开一个上下文,我可以在这里使用 @Past Chats 指令,然后选中之前的一个上下文,我们输入一个问题,检查一下之前都做了什么,回车

它就会总结我们之前这个 Chat 的内容,给到这个当前的上下文,过长的上下文是 Cursor 变傻降智的原因之一。
Cursor 显得很傻,像是降智了,除了用户过长的上下文,其实 Cursor 本身也有一定的原因,Agent 模式下,Cursor 会做很多事情,我们发送一个请求后,Cursor 会先理解请求,分析我们的请求内容和代码库的上下文,理解我们的任务要求和目标,然后搜索代码库,这一步可能会搜索代码库、文档,或者是网络内容,然后再规划任务,这一步会将任务分解成更小,更细粒度的步骤,并且执行过程还会从可用的上下文中学习,再然后执行任务,这一步会根据整个代码库进行必要的修改,还有可能会建议我们运行某些终端命令,或者建议我们应该在 Cursor 之外,执行一些步骤,再然后是验证结果,Cursor 会自动应用所有更改,然后确认是否正确,如果发现了一些问题或者说 Lint 错误,就会自动尝试去修复,最后一切都 OK 了,这个任务才算是结束。
这是一个非常复杂的工作流,上下文传递发生在每一个环节中,随着 Cursor 的不断更新,这个工作流会越来越复杂,以支持更多、更智能的功能,而支撑这些工作流运行,必然少不了预设的系统提示词,这个内置的系统提示词,还会越来越复杂,而我们作为用户,获得了更强大的功能以及更好的体验,但是也在一定程度上,损失了一些大模型的清爽调用,这也是很多人吐槽降智、实锤降智的点。
因为有人在 Cursor 客户端中使用 Claude-3.7-sonnet,和在 Claude 客户端中发送了同一个问题,结果 Claude 客户端的效果更好,但是我们要明白一点,它们之间没有可比性,Claude 的客户端,必然也有它的系统提示词,或者说内部指令在,而 Cursor 作为一个 AI 编辑器,需要考虑的方面有很多,显然目前 Cursor 的 Agent 模式,强大又智能的任务规划,整体的适配性更强,那如果我们想要清爽一些的模型调用,使用 Manual 模式会好很多,因为 Manual 模式,没有那么多复杂的自主性操作,所以新版本中,模型降智、地域性降智、会员超额降智等等等等,归根结底都只是大家的一厢情愿。
当然,以上信息是我个人根据差异测试、社区讨论,以及使用经验推测得出的结论,而且上面两种情况,是基于用户输入的提示词足够全面,且清晰的前提下,如果提示词,或者说需求描述本身就存在问题,那就另说了,关于一份好的提示词,或者说一个好的问题,说到底还是提问的技巧,加 Prompt 技巧,我们就不再赘述了,有兴趣的话,可以看一下我之前总结的 《一文搞懂Deepseek》一文,对于问题与提问介绍的会很清晰。
7.2 对 cursor 给出的回答进行修正
某天凌晨,真的是凌晨,有位朋友给我发了一大段私信,我总结了一下,大概意思就是说新版本在更新之后,他基本上就是 Agent 模式一把梭,然后 Agent 模式的自主性比较强,任务拆解后,Agent 一步一步的执行修改,经常会出现前几步没毛病,执行着执行着就开始走偏了,这个时候他就很头疼,因为重新编辑任务发送还需要,等待一步一步执行太浪费时间,不重新编辑,后面的步骤生成又是不对的,改起来很麻烦,问我有没有遇到过这种情况,以及有没有什么好的解决方案。
这个问题其实很常见,因为大部分朋友在 Agent 模式下,让模型执行一些大的任务,Agent 模式会进行多步骤任务拆解规划,再去分步骤执行,不可避免的,其中某个环节在多步骤的上下文传递中,就会有一些遗漏,针对这个问题也要分情况讨论。
我们先选中一个稍微长一点的上下文,如果只是一个大任务中的某一个步骤,任务输出有问题,我们可以等这个大任务执行完成之后,再发送针对这个任务步骤的补充修改,那如果整个大任务,绝大多数步骤输出都有问题,我们就要回到发送任务需求的这个聊天框进行回滚,并重新发送问题
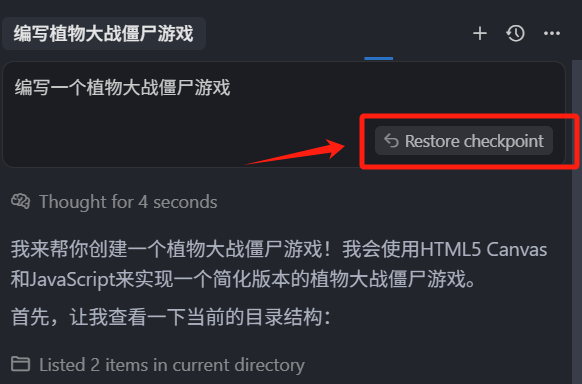
可以直接点击聊天框,右下角的 Restore checkpoint,点击之后就可以通过 Checkpoint 标记,把代码回滚到这个任务发送之前,然后我们可以重新编辑这个需求再次生成。
那如果大任务拆解后,前面步骤输出没有问题,但是后面步骤有问题,当我们看到任务输出有问题时,就可以直接点击输入框下方的 Stop 按钮暂停结果的生成
然后补充描述,再让它继续生成就可以了,那如果这个大任务已经输出完成了,但是后半部分的任务又都不对,Cursor 在新版本中,还上了一个不起眼的小功能:在 Agent 模式中,Cursor 每执行一个小任务时,都会先输出一段文字,告诉我们它接下来要做什么了,我们可以直接把这个鼠标,悬浮到每个小任务前的文字上,可以看到,鼠标悬浮到每个任务的文字描述上时,在文字左侧都会有个加号小图标,点击
就可以在加号位置插入一个 AI 输入框
我们可以通过这样的方式,截断下面的输出,然后重新输入补充描述,回车,接着执行后面的任务,插入输入框前面的内容是不影响的,只会截断我们后面的内容。
处理这种问题只有上面这 3 种方式,当然,最重要的其实还是问题本身的描述,在用 Agent 模式执行一个大任务时,一定要把上下文背景信息给足,最好是单独给这个任务写一个 md 文档,描述清晰需求,然后 Chat 输入框直接引用这个 md 文件,让 AI 审查一下这个需求,确保没有什么遗漏,最后再引用这个 md 文档,让 Cursor 根据,这个需求文档去执行。
如果这种情况下还是跑偏了,那就使用上面说的方案,如果还是不行,那就需要考虑这个任务是不是太大了,要不要做一下需求拆解。
八 新玩法
8.1 MCP
介绍完新版本中Cursor 使用过程中的一些小技巧,我们接下来来给大家介绍,新版本 Cursor 的一些新玩法,或者说思路,这一趴我们只介绍两个内容,Rules 和 MCP。
先来说说最有用也是最没用的 MCP,其实对绝大多数普通用户来说,使用 SSE 的方式,调用 MCP Server 是最简单的,只需要配置 SSE 链接就可以了,但是,市面上绝大多数的 MCP Server 都是源代码,没有被托管到网络服务器,这种只能使用 Stdio 模式,这无疑大大增加了用户的负担,我建议没有开发经验的朋友们,可以使用魔搭社区的 MCP 广场(https://www.modelscope.cn/mcp)魔搭社区给部分 MCP Server 都部署了一下,也就是他帮我们托管了一部分 MCP Server,所以我们在这个平台上,找到带有 Hosted 标记的 MCP Server
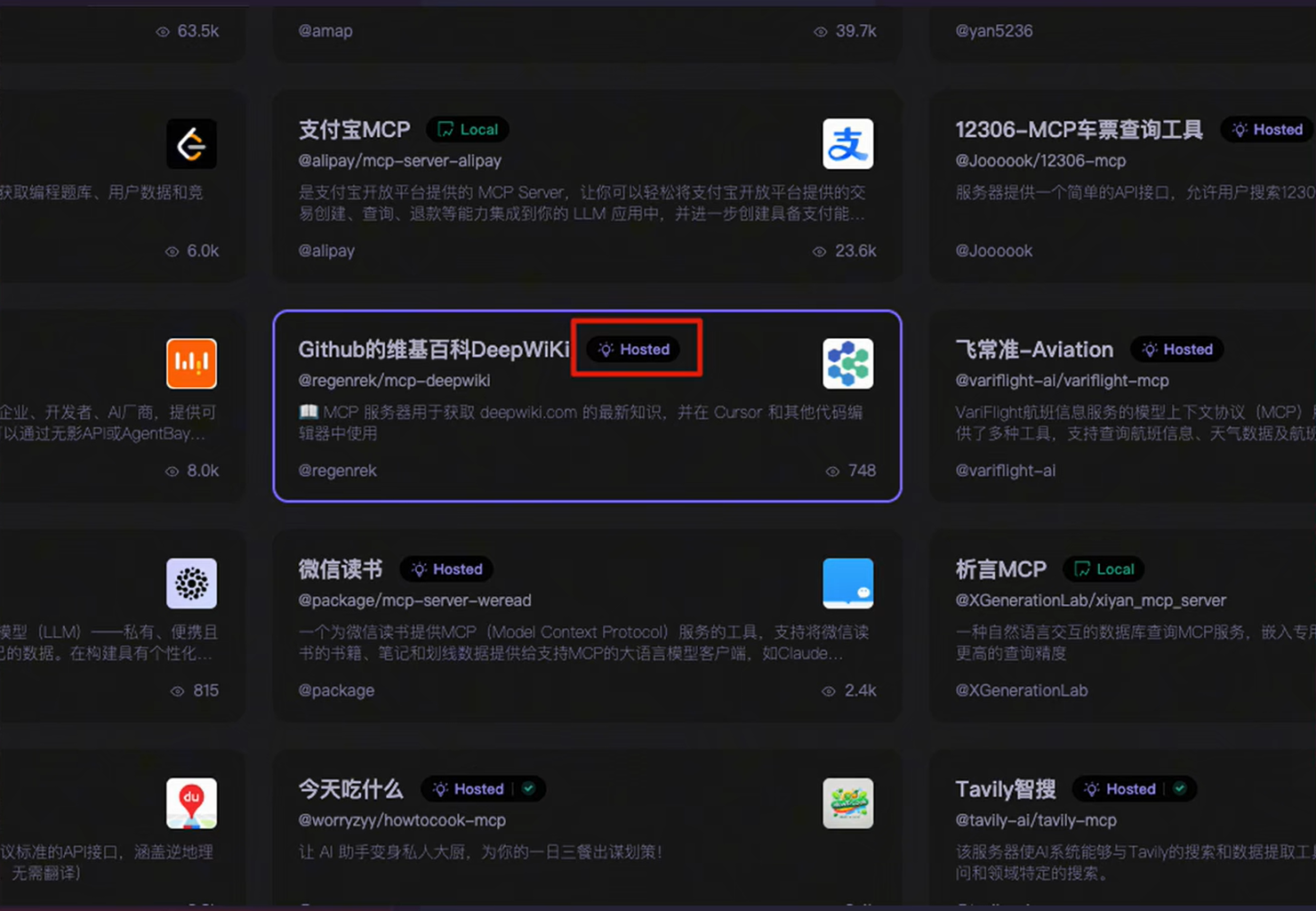
点开就是支持 SSE 的
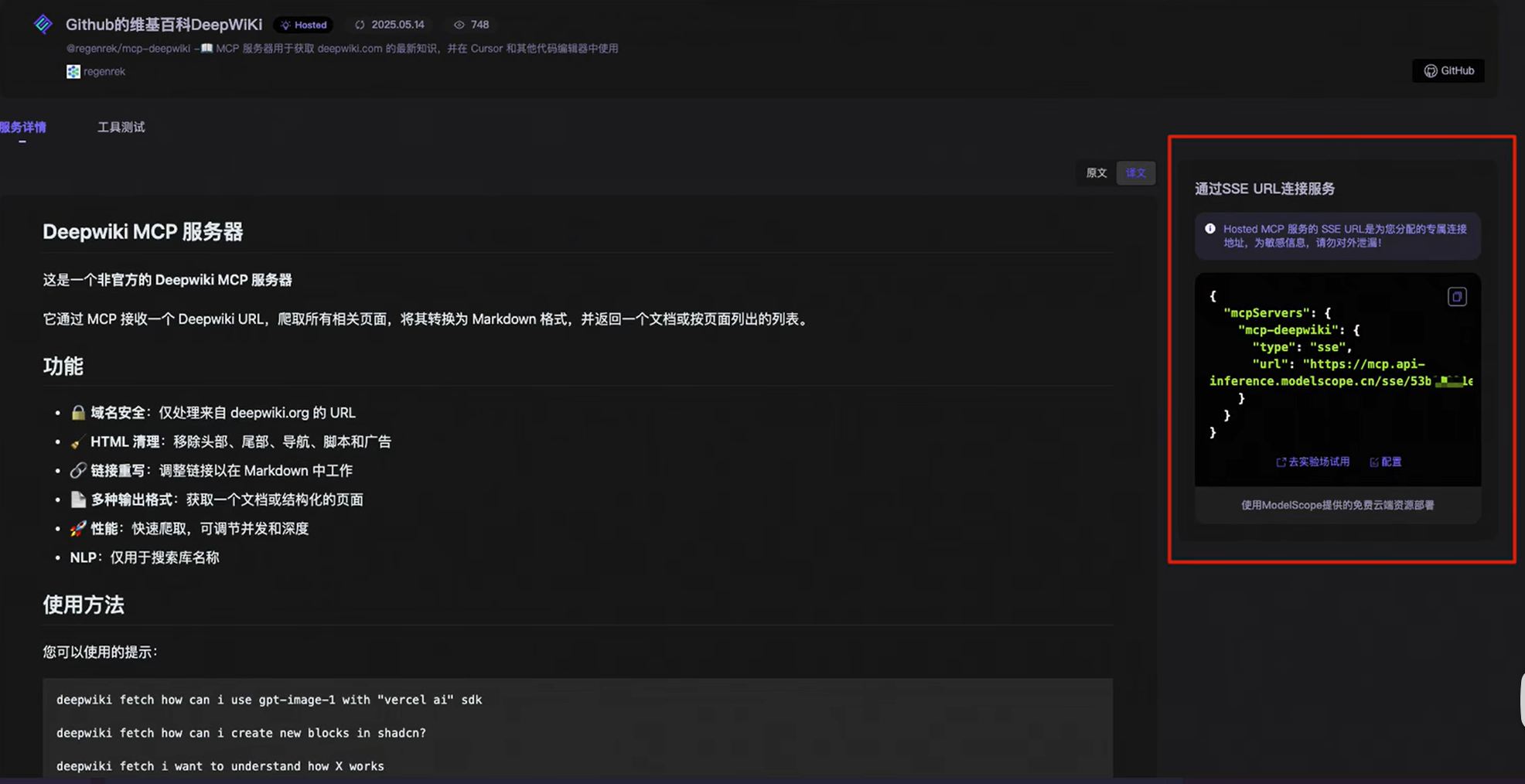
我们可以点开之后,直接复制右侧的 JSON,在 Cursor 中添加 MCP Server 就可以了,这会极大降低我们的负担,那对于编程人员,MCP 广场之类的项目多了去了,网上搜几个看到哪个 MCP Server,好玩的都可以简单尝试一下。
说到正题,其实我个人看来,MCP 对编程开发的帮助并不是特别大,看我视频的大部分都是为了编程对吧,所以大 家不要过分的关注MCP,不如把精力放在 Rules 上,当然不是说 MCP 没用,我们每个人在使用 MCP 之前,都应该先理清自己的工作流,然后基于自己的工作流,去 MCP 广场之类的项目看看,看有没有在工作流中,能帮助到自己的 MCP Server,这是一个正确的打开方式。
其实我个人到目前为止,除了不断尝试使用一些比较感兴趣,有意思的 MCP Server 之外,真正能在开发中帮助到我的,只有一个 MCP Server,那就是 Firecrawl,之所以能够用到它,是因为有些动态网页链接,Cursor 解析不了,这个时候我会用 Firecrawl 爬取,并且输出格式化内容,还有一个点是,Cursor 的 Web search 功能并不是很全面,特别是对于中文内容,一些特殊的中文内容,我也会用 Firecrawl 的 Search 工具,当然能提供爬取和 search 能力的 MCP Server,有很多,我用 Firecrawl 是因为我给f Firecrawl 付费了,大家不要误会,我是因为其他地方需要调用它的 API 才付费的,并不是单纯为了使用 MCP Server 而付费,因为 Firecrawl 在我开发中,使用的也不是特别频繁。
然后我也会经常性的体验,一些比较新奇的 MCP,比如使用 Blender MCP Server,连接 Blender 通过自然语言建模,比较好玩,我就尝试一下,但是也仅此而已,因为它不属于一个好用、实用、且常用的功能,仅仅是因为新奇,玩完就删除了配置,当然,如果我们并不是为了开发而使用 MCP Server,那其实还是有的玩的,毕竟,目前的花里胡哨的 MCP Server 一大堆,但这个,我们使用其他支持 MCP Client 的客户端产品,体验要比 Cursor 会更好,而且,这就不是我们这期视频讨论的重点了,我们的讨论,应该始终围绕在 AI 编程这件事本身。
我想和大家说的是,单纯为了开发提效,在 Cursor 中使用 MCP Server,并没有太大的意义,因为 Cursor 本身针对编程的功能,基本上已经很全了,我们开发常用的一些工具,Cursor 基本也内置了,我也不建议大家在 Cursor 中,配置太多的 MCP Server,Cursor 官方也不建议,甚至如果你配置了很多 MCP Server,Cursor 还会提醒你,因为大量的 MCP Serve Tool,真的会给 Cursor 降智,所以大家如果有配置很多 MCP Server,不用的话就禁用掉,省得妨碍日常开发。
我们不妨换个思路,大家可能都会使用 Cursor 开发一些产品,所以相比于我们在开发中,想着怎么去使用 MCP Server 提效,不如想一想如何在开发的产品中,基于 MCP 的能力去开发,去创造一些有趣的 AI 产品,或者使用 Cursor 结合特定场景的工作流,开发一些有趣的 MCP Server 给用户去使用,我认为这才是我们玩 Cursor,这样一个 AI 编程产品,核心要关注的点。
8.2 Rules
我们接着说 Rules 的玩法,也是我认为很重要的一节,其实本来是想通过一个案例,带大家完整体验一下整体的项目流程,以及怎么基于流程规划出一套工作流 Rules,但是这个视频已经很长了,还是下次有机会再录吧。
我简单说一下思路,Rules 功能出现以来,如何写一个好的 Rules,一直是社区里激烈讨论的点,但是在我看来,无论以什么样的格式写,中文还是英文都不重要,重要的是规则中要体现,什么情况下要使用这个 Rules,应该怎么怎么样,绝对不要怎么怎么样,最后再给一个正反示例就 OK 了,硬要给他们个格式的话,其实核心就是,使用场景、关键规则和示例 3 块儿。
那举个例子,假如我们手写一个适用于所有 md 文件的文档规则,那首先要有一个一级标题,然后我们要把三个核心模块,作为二级标题写上,最后补充这三块内容,示例的截图如下:
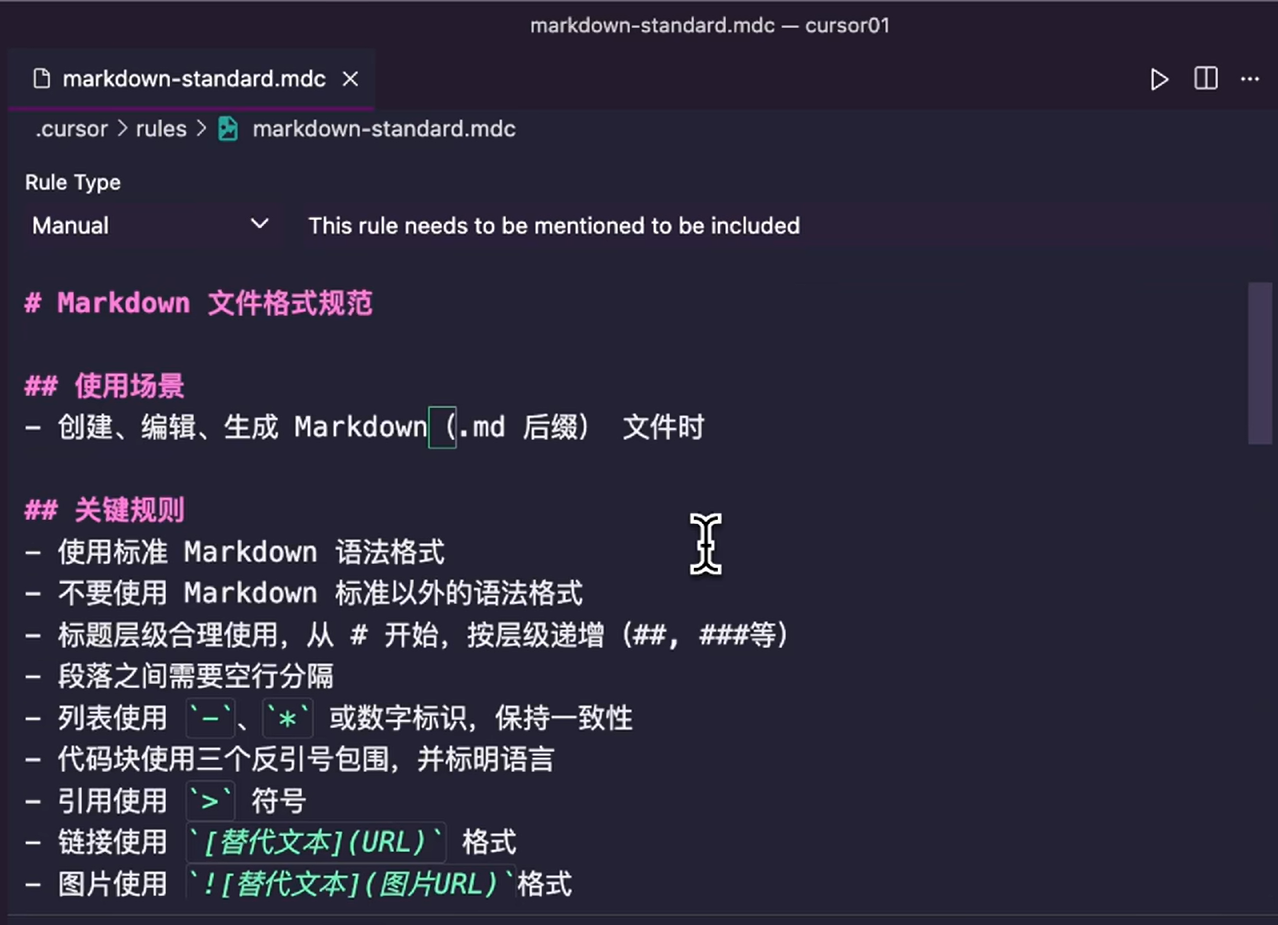
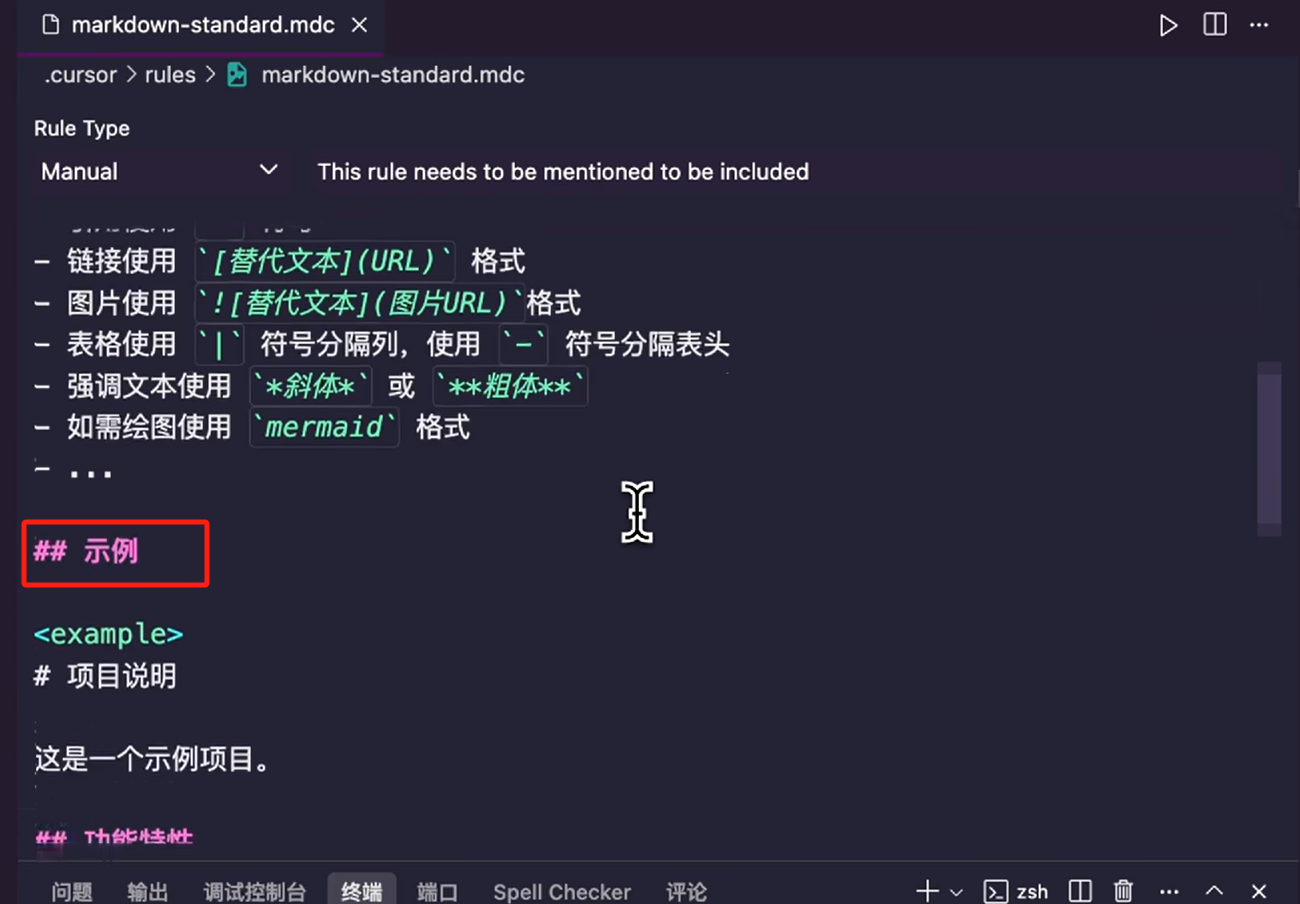
这是一个非常简单的例子,这里的使用场景一句话就可以概括,如果是复杂 Rules,我们可以多写几个,但是注意要尽量的简洁,## 关键规则这里,要怎么做、不要怎么做,可以根据自己的需求多写几个,## 示例这块就是给出一个正确的示例,然后再给出一个错误的示例。
这就已经是一个及格的 Rules 了,写完之后,我们再去选中一个类型,由于这个规则是要匹配所有的文档文件,也就是匹配 md 后缀文件,所以我们选择的是 Auto Attached 类型,然后在后面输入匹配所有 md 文件的正则,那就是 *.md,回车,保存一下。这个用于项目下所有 md 文档的规则就写好了。

当然它很简陋,那如果我们想要所有的规则生成时,都按照我们这个基础规范去生成,甚至想让生成的 Rules,按照固定的方式去命名,这就是一个很适合 Rules 的点,那我们就可以去写一个“用于生成规范规则”的规则文件。
你可以使用 Generate Cursor Rules 指令,输入我们想要一个什么什么样的规则,生成完了自己再去改一改,那为了节省时间,我们这里直接创建一个 Cursor Rules MDC 文件,回车。
然后我们直接粘贴一个我已经写好的一个规则,保存。
# Cursor Rule 规则格式规范
## 规则文件模板结构
\`\`\`mdc
---
description: `根据规则内容,生成包含关键场景、动作、触发条件、结果、格式的内容,限制在 150 字以内`
globs: 空白或模式 (例如: *.js, *.ts, *.py, .vscode/*.json, .cursor/**/*.mdc)
alwaysApply: {true 或 false}
---
# 规则标题
## 使用场景
- 何时应用此规则
- 前提条件或要求
## 关键规则
- 简洁的、列表形式的行动规则,模型必须遵循
- 始终执行 X
- 绝不执行 Y
## 示例
<example>
好的简洁示例及其说明
</example>
<example type="invalid">
错误的简洁示例及其说明
</example>
\`\`\`
## 文件组织
### 规则文件位置
- 路径:`.cursor/rules/*.mdc`
- 扩展名:`.mdc`
### 规则命名规范
- 文件名使用 kebab-case 格式
- 始终使用 .mdc 扩展
- 让命名可以直观描述规则的目的
- 私有规则:以下划线 _ 开头,该规则将位于 gitignore 中,例:`_rule-name.mdc`
- 规则文件命名需要根据规则类型添加后缀,例:`rule-name-{auto|agent|manual|always}.mdc`
- auto: 自动规则
- agent: 代理规则
- manual: 手动规则
- always: 全局规则
### Glob 示例
不同规则类型的常见 glob 模式:
- 核心规则:.cursor/rules/*.mdc
- 语言规则:*.js, *.ts, *.py, *.cpp, *.hpp
- 测试规则:*.test.js, *.test.ts, *.test.py, *.test.cpp, *.test.hpp
- 文档规则:docs/**/*.md, *.md
- 配置规则:*.config.{js,json}, *.json, *.yaml, *.yml
- 构建产物规则:dist/**/*
- 多扩展名规则:src/**/*.{js,jsx,ts,tsx}
- React 组件规则:*.tsx, *.jsx
- Vue 组件规则:*.vue
## 必需字段
### 前置信息
- description: `根据规则内容,生成包含关键场景、动作、触发条件、结果、格式的内容,限制在 150 字以内`
- globs: 空白或模式 (例如: *.js, *.ts, *.py, .vscode/*.json, .cursor/**/*.mdc)
- alwaysApply: {true 或 false}
### 正文
- 使用场景
- 关键规则:最关键规则的简短总结
- 示例:有效和无效示例
## 格式指南
- mdc 规则文件中使用简洁的 Markdown 语法
- 仅限使用以下 XML 标签:
- <example>
- XML 标签内容或嵌套标签必须缩进 2 个空格
- 如果能更好地帮助 AI 理解规则,可以使用表情符号和 Mermaid 图表(但不要冗余)
## 关键规则
- 规则文件将始终位于和命名为:`.cursor/rules/rule-name-{auto|agent|manual|always}.mdc`
- 规则将永远不会在 .cursor/rules/** 之外创建
- 你应该总是会检查是否在所有 .cursor/rules 子文件夹下存在要更新的现有规则
- 规则正文中,除了使用场景、关键规则、示例,你也可以根据需求扩展更详细的规则内容,但请注意内容简洁有效
- 规则类型前言部分必须始终在文件开头,并包含所有 3 个字段,即使字段值为空 - 类型如下::
- 手动规则:如果请求手动规则 - description 和 glob 必须为空,alwaysApply: false 且文件名以 -manual.mdc 结尾
- 自动规则:如果请求的规则应始终应用于某些 glob 模式(例如所有 typescript 文件或所有 markdown 文件) - 描述必须为空,alwaysApply: false 且文件名以 -auto.mdc 结尾
- 全局规则:全局规则 description 和 glob 为空,alwaysApply: true 且文件名以 -always.mdc 结尾
- Agent 选择规则: 此规则不需要加载到每个聊天线程中,它服务于特定目的。description 必须提供全面的上下文,包括代码更改、架构决策、错误修复或新文件创建的场景。glob 为空,alwaysApply:false 且文件名以 -agent.mdc 结尾
- 对于规则内容 - 专注于明确的行动指令,无需不必要的解释
- 当规则只会在某些情况下使用时(alwaysApply: false),描述必须提供足够的上下文,以便 AI 可以自信地确定何时加载和应用规则
- 使用适合 Agent 上下文窗口的简洁 Markdown
- 在 XML 示例部分中始终使用2个空格缩进内容
- 虽然没有严格的行限制,但要注意内容长度,因为它会影响性能,需要专注于帮助 Agent 做出决策的关键信息
- 规则示例中总是包括一个有效的和无效的示例
- 永远不要在 glob 模式周围使用引号,永远不要将 glob 扩展与 `{}` 一起分组
- 如果请求规则或未来行为更改包括错误上下文,这将是在规则示例中使用的绝佳信息
- 在规则创建或更新后,响应以下内容:
- 自动规则生成成功: {规则文件相对路径及文件名}
- 规则类型: {auto|agent|manual|always}
- 规则描述: {描述字段的确切内容}
上面这个就是在我们想要所有的规则生成时,都按照我们这个基础规范去生成,也就是用于生成规范规则的规则文件。
这个“规则文件模板结构”其实就相当于是 Rules 的一个正确的示例,然后下面是文件组织规则,规则文件位置,**规则命名规范**以及 Glob 示例。这个 Glob 示例就是 Auto Attached 模式下,我们写的这个正则表达式的示例。然后下面是必需字段,前置信息,还有正文的一些内容,格式指南,最重要的就是关键规则,其实核心的规则,都在这个关键规则里面写着.
那这个规则也是我目前在使用的,所以改的比较细,因为它还涉及一些 Rules 文件命名,以及头部的类型输出规则,当然,由于 Cursor 自动生成规则,一直以来都有 BUG,虽然官方也在积极的改进,并且自己搞出了一个 Generate Cursor Rules,但是依然还是有 BUG 的,我们生成规则文件后,还是要手动的去选择规则类型,配置类型信息,
我们选中 Agent Requested 类型,然后输入 Description:当需要创建规则、更新规则或从用户那里学习应该保留为新规则时使用。保存,我们使用的是 Agent Requested 类型,这种类型规则 Cursor 收到问题之后,会根据问题的语义匹配 Description,决定是否使用这个规则,那接下来只要匹配到我们有创建规则、更新规则或者是从用户那里学习应该保留为新规则的类似语义需求,就会使用。
Agent Requested 类型:把规则的使用权交给了 AI,由 AI 来根据我们填写的规则描述,和我们的问题去匹配,并判断是否自动使用这个规则。
8.3 需求文档 prd
如果我们有个想法,想要开发一个产品,那第一步首先要把想法落成需求,要有一个流程明确、架构完整、逻辑严谨的需求文档,也就是 PRD ,这是整个项目开发中最不可或缺的一部分。
现在我有一个番茄时钟 APP 的想法,这个 APP 用来管理用户的碎片化时间,提升专注度,我们有一个核心的想法,但是也只是一个想法,需求并不是很明确,为了落实完善一下想法,我们在根目录创建一个 docs 文件夹,然后在这个文件夹下,创建一个 prd 文件
把我们能想到的想法都写下来,这里我直接粘贴一下保存,
我想开发一个番茄时钟 APP,用来管理用户的碎片化时间,提升专注度.
核心需求:用户可以基于自己的碎片化时间设置一个专注时长,设置之后可以选择或者自行填写一个标签用来标识这段时间再做什么,设置好之后点击开始即可进行倒计时,倒计时全屏展示极简风格的数字时钟,中间可以点击暂停、继续、结束时钟,或者直到倒计时结束,需要记录用户每个专注的时长并做出每日、每周、每月的统计报表。用户也可以预设每天、每周、每月预期要专注的事项及时长,类似一个 todo list,预设的内容需要按预设时间展示给用户,用户点击即可通过倒计时的方式完成这个预设专注。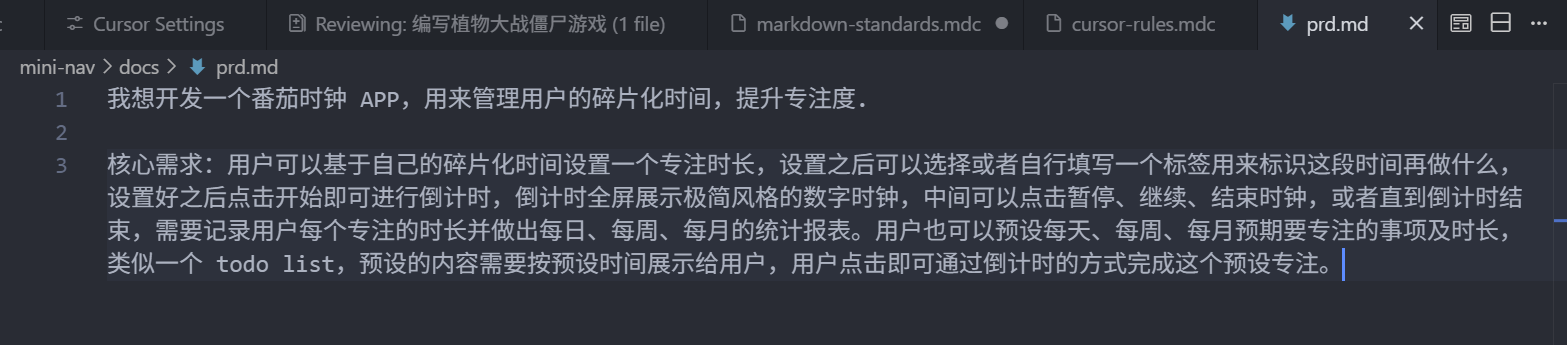
假如现在脑子里就这些东西,我们可以让 AI 帮我们完善一下需求,我们打开一个新的 Chat,然后输入这样一段话,回车
我想开发一个APP,@prd.md 这是我的核心需求,请你分析、完善、优化这份需求,让整个 APP 逻辑完整,输出 prd。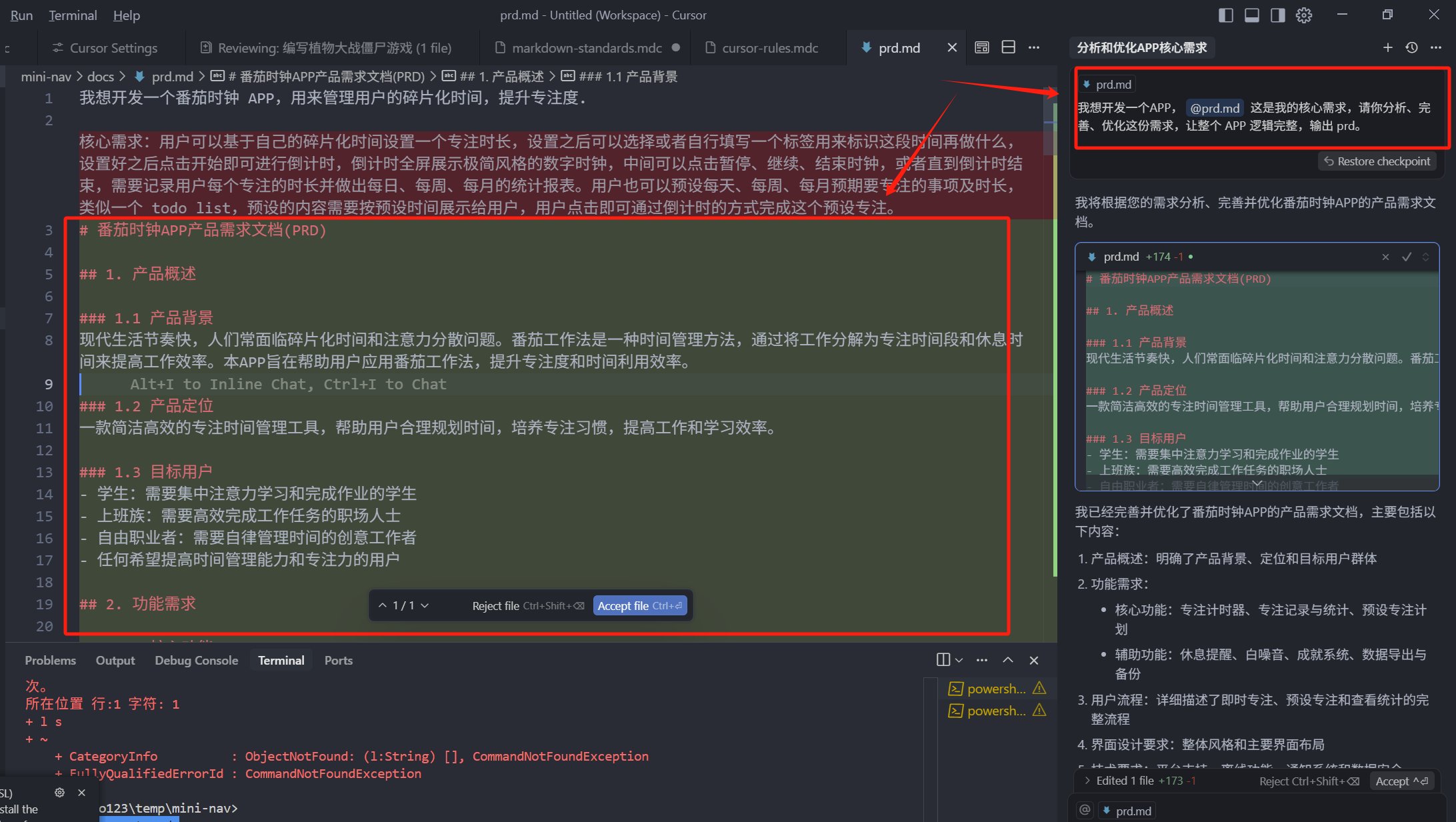
生成完成之后,我们就可以检查一下,这份 PRD 和我们想象中的产品是否有冲突,有冲突的话就继续改,改到满意为止,我这里演示用,就默认已经改到我满意了,在产品开发中,需求文档一旦确定之后,开发过程中应该始终遵循这份文档,在开发完成之前,非必要就不要更改了。这个过程中,如果有新的想法想要修改需求文档,不要直接编辑这份文档,而是重新写一份文档,并且给一个新的版本号,作为下一期的需求,那在开发中,我们应该始终按照需求文档的边界去开发,开发完成一个需求文档中的内容,再考虑迭代的需求,而不是一有新的想法,脑子一热就去改。
需求有了之后,我们也可以考虑让 Cursor 基于需求文档,帮我们生成一套原型界面,这样可以更直观的感受一下,整个产品的界面逻辑,还是在 docs 目录下,我们创建一个 pr.md 文件
还是同样的逻辑,我们需要基于自己的诉求,把能想到的,所有优化原型输出的提示词都写一下,这里我也粘贴一下,保存
1. 基于核心需求参考市面优秀竞品基于用户体验完善需求并确定整体的交互逻辑。
2. 设计并规划原型界面时,应该确保整体架构的合理性。
3. 应该基于 APP 设计规范并参考市面上优秀的 APP 设计方案,确定并设计一套统一、现代化的高保真原型页面,原型界面要具备优秀的视觉以及交互体验。
4. 使用 HTML 输出原型界面,使用原子化 CSS 的方式写样式,也可以使用优秀的开源 UI 组件让界面更精美且统一。
5. 每一个页面应该有一个单独 HTML 文件,将所有页面以 iframe 的方式平铺展示在入口页面中,这样更直观,而不是使用链接跳转,还应该给每个页面的展示区使用 CSS 绘制出 iPhone 15 的手机框,让其更像一个真实的手机 APP,每个页面的 UI 风格(色彩圆角、间距、字体、图标等等)应该保持统一。
6. 请在完成所有需求的前提下,尽量使页面更简洁,降低用户的心智负担。
7. 原型应该输出在根目录下的 pr 文件夹下还是和上面流程一样,我们让 AI 系统的优化一下这份提示词,新开一个 Chat,输入需求,回车
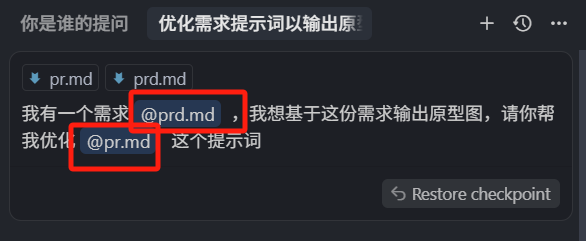
我有一个需求 @prd.md ,我想基于这份需求输出原型图,请你帮我优化 @pr.md 这个提示词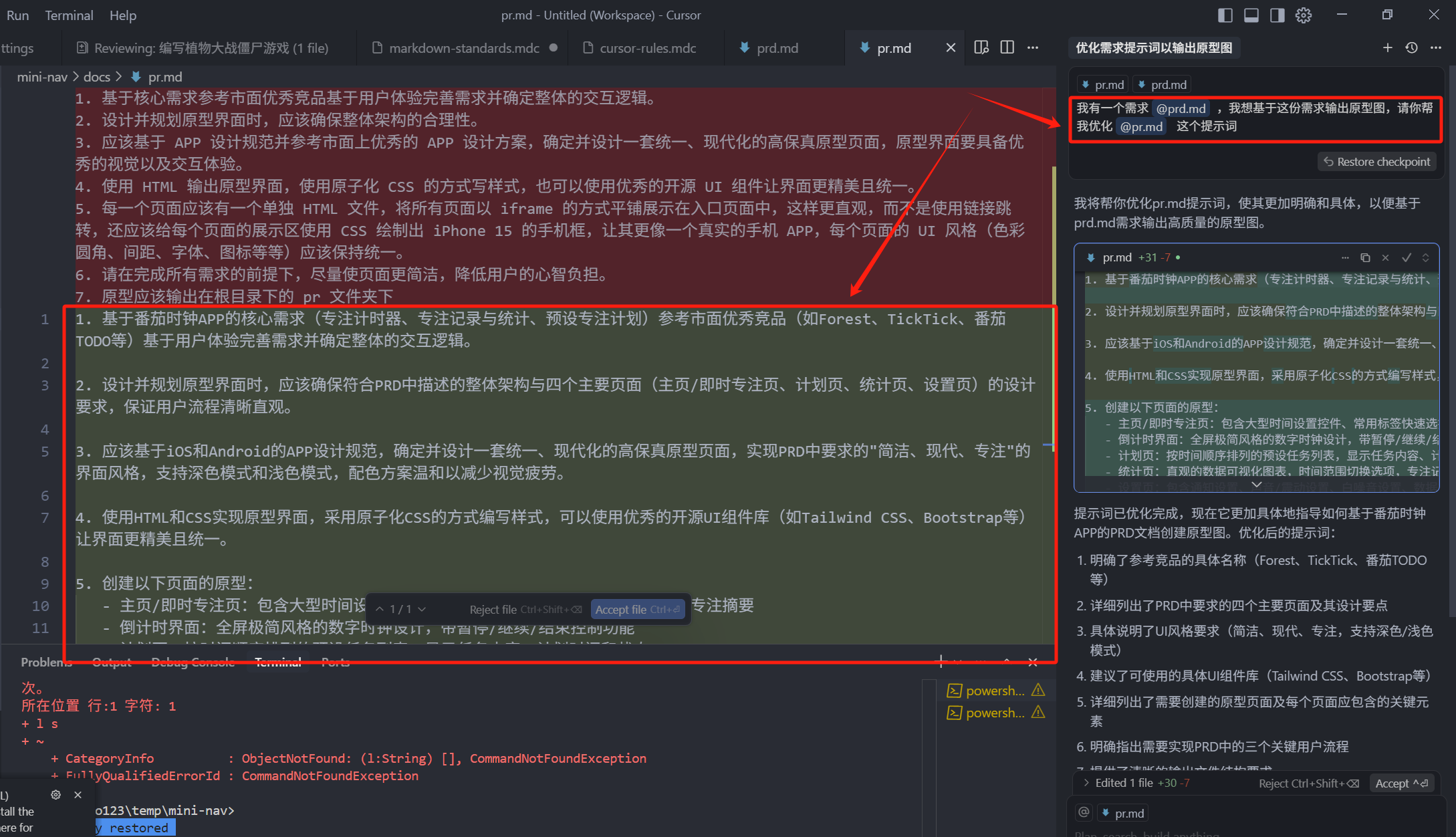
它输出完成之后,我们就可以检查一下,这份优化后的提示词,是否符合我们的需求,还是老样子如果不符合,那就改到满意为止,最后我们再打开一个新的 Chat,然后让 AI 帮我们输出原型设计
那这里我就不浪费时间了,给大家看一下,之前基于这份需求和提示词,生成好的原型界面,因为这个原型生成太耗费时间了。
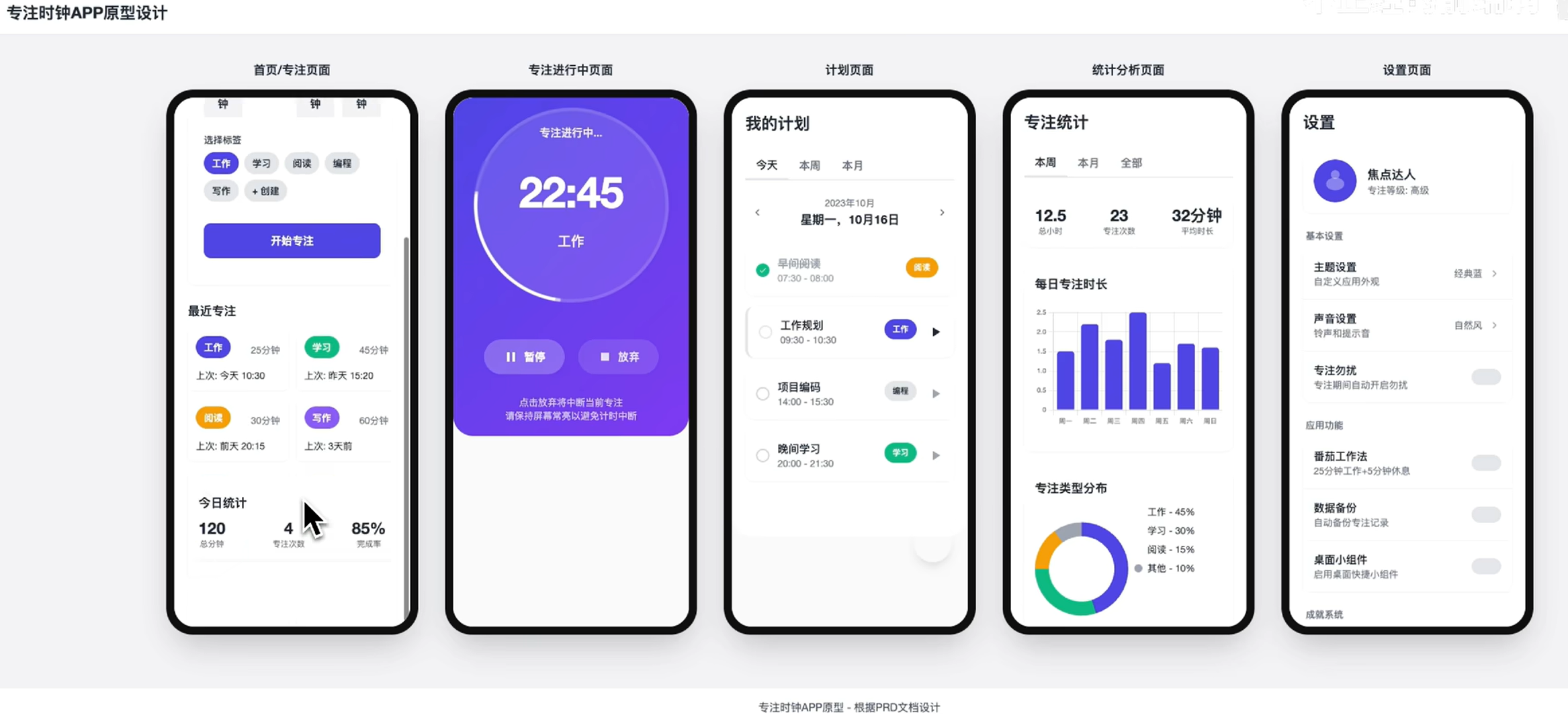
看上去还可以,但是又不是那么好对吧,不过作为一个简单原型来验证需求,是够用了,这是比较正常的,其实大家可能在网上会看到一些,让 Cursor 生成的很漂亮的原型界面,要知道他们的前提是需求比较大众化,市面上有不错的竞品可以让 AI 抄袭,那我们现在写这个 APP 需求,是我临时起意,把番茄时钟和待办这两个需求,拼凑了一下,再加上市面上这个领域没有特别火的产品,本身也是一个小众需求,所以它的结果相对真实一些,可以给大家做参考。
当然,我们的提示词还是比较随意的,还有很大的优化空间,因为 AI 生成之后,我们没有做任何改动当然只是为了作为 demo 用,就不抠细节了。
原型确定之后,接下来我们还要确定一下技术方案,输出技术方案文档、架构文档,如果我们要开发的产品,有数据上的要求,我们还要生成一份数据库设计文档,甚至是接口文档,如果不涉及后端,只是一个工具型的产品,那只输出技术方案文档就可以了,其实和上面两步一样,我们可以提供一个简单的核心需求,让 AI 帮我们去完善这些文档。
当然,完善的过程,也需要我们不断的去修改以及补充,后面我就不演示了,简单说一下思路,那针对上面的这些文档输出,我们也可以给每份文档设置 Rules 规则,来约束文档的生成格式,比如需求文档,我们可以给它一个规则,来约束需求文档的内容格式,甚至可以写一个需求文档的模板,在需求文档生成的规则中,配置关键规则,基于需求文档模板生成一个需求文档,那技术方案、架构文档、数据库设计文档、接口文档都是类似的,都可以配置模板以及规则约束,按照模板或者是规则约束去生成。
这些都做完之后,不妨我们再打开一下思路,我们是不是可以做一个工作流的规则,那这份规则约束,当我们基于一份需求文档执行任务时,帮我们把需求拆解成多个任务步骤,然后创建需求文档的待办文档,按照任务步骤去依次的执行,每执行完一个任务时,任务待办清单中,就去标记该任务已经完成了,每次修改任务时,在任务待办清单中记录更改的内容描述,每一次任务执行前,都应该参考待办清单,这样的话,我们让 Cursor 完成需求时,它就会根据我们的工作流规则,依次执行。
当然,这里的工作流规则,我只是举个例子,给大家简单开阔一下思路,这个例子也很简陋,工作流是可以很细的,其实你会发现,随着 Rules 的不断增加,我们对于特定任务的规划越来越细,久而久之就形成了工作流,不知道大家有没有用过 V0、Bolt,这种被誉为 L3 级别的 AI 编程产品,或者是 Manus、扣子空间,这种黑盒 Agent 产品,他们都是你给它一个需求,它帮你规划任务,然后按照流程完成任务,其实他们也是类似的,都规划了一套工作流,让用户的输入任务,随着工作流逐步去推进,我们在使用 Cursor 的过程中,慢慢形成的工作流,和这些产品内部的实现其实是类似的,只是我们的工作流,是根据自己的需求逐步构建的,所以它的适用性更窄,但是指向性会更强。
那说到这里,聪明的朋友已经想到了,Cursor 中的 Agent 模式,其实也可以理解为一种内置的工作流,因为它从需求理解,到搜索代码库,到计划变更,再到执行更改,再到验证结果,最后任务完成。
我们在使用 Agent 模式时,其实都是按照这样一套 Cursor 内置好的流程规则去走的,当然,这只是一个大的流程步骤,Cursor 中每个流程还划分的很细,因为每个流程中负责的事情都不一样,每个流程中,也可以调用一些不同的工具,去处理一些不同的需求。
不出意外的话,这里肯定会有人问,有没有一套拿来就能用的通用型工作流,我可以很负责的告诉大家,有,但是不建议拿来直接就用,严格意义上来讲,我们每个人的需求、技术能力、,项目大小都不同,适用的工作流其实会有很大的差别,就比如一个非常完整,各方面考虑的都非常周到的,通用型工作流,对一些小产品、不太懂编程的群体来说,简直就是灾难,还不如不用,所以我建议大家要先有这个意识,只要你有用 Rules 约束流程的意识,随着对 Cursor 越用越熟悉,慢慢的你会写出很多 Rules 文件,然后,你会不由自主的想要通过工作流 Rules,将大部分的 Rules 串联起来。
当然,我们可以参考一些优秀的通用工作流,来加速这个流程,但是不要拿来就用,拿别人的工作流,哪怕是所谓的通用型工作流,都不如不用,因为你没有办法把控,别人做好的工作流中的每一个细节,在 AI 的任务执行中,每一个环节的偏差,都会带来很大的影响,如果大家不信,在 Cursor 社区中,其实有很多人讨论通过 Rules 做工作流,并且逐渐诞生了几个所谓的开源通用工作流。他们的仓库地址如下:
不建议拿来就用,参考即可
大家可以去体验、学习一下这些所谓的通用工作流,大部分人估计都看不太懂,还有一部分人,对这些过于格式化的工作流极其不适应,更何况去很好的使用它,所以根据自己的能力,逐步增加项目中的 Rules 规则,然后逐步将自己的一些 Rules,通过一个工作流 Rules 串联起来,慢慢的扩展,参考优秀的工作流 Rules,一点一点,汲取对自己有用的工作流写法,填充到自己的工作流 Rules,这整个过程中,你不仅学会了如何更好的 AI 编程,也了解了整个产品的开发流程,同时还能对 AI 中的 Agent、Workflow,两个概念有着更深刻的理解,这才是最好的方式。